Java集合框架全面解析:List、Set、Map、迭代器、泛型、队列、栈与综合实战。
集合的介绍 什么是集合 开发和学习中需要时时刻刻操作数据,如何组织这些数据就是一个很重要的工作,比如有一些学生的信息需要进行存储,这时候就需要一个“容器”来存储这些数据,我们可以想到数组。数组就是一种容器,用来存放这些数据。
数组的劣势:不灵活,数组的容量不能改变,不能扩容,插入和删除数据还要伴随着元素的移动,非常不人性化。
数组的优势:性能高。
所以数组远远无法满足我们对数据的组织和管理的需求,所以我们需要一种更强大、更灵活、容量随时可变的容器来存储我们的数据
我们可以牺牲一些性能损耗,换取一个性能更高的容器。这些容器就叫做集合。
集合只能存储引用类型的数据 ,但是类似于1234、3.14这些基本数据类型也可以存储,只不过存储的是它们所对应的包装类,本质上存储的也是引用数据类型。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 package com.leo.unit1;import java.util.ArrayList;public class Demo1 { public static void main (String[] args) { ArrayList list = new ArrayList (); System.out.println(list); list.add(123 ); System.out.println(list); list.add(3.14 ); System.out.println(list); list.add("HelloWorld" ); System.out.println(list); list.add("雷欧教育" ); System.out.println(list); System.out.println("==================" ); for (int i = 0 ; i < list.size(); i++) { System.out.println(list.get(i)); } } }
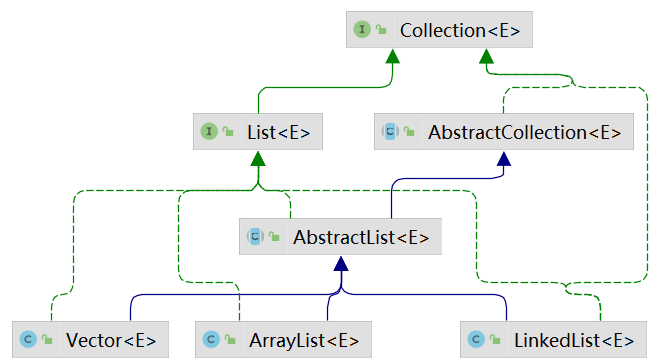
Java中集合的体系 List集合
常见的子类有ArrayList、LinkedLIst、Vector
Set集合
常见的子类有HashSet、LinkedHashSet、TreeSet
Map集合
常见的子类有HashMap、LinkedHashMap、TreeMap、Hashtable、ConcurrentHashMap
Collection接口 Collection接口是Java中List和Set集合的顶层接口,Collection中定义了一些所有集合都可以使用的方法
*方法名* *描述*
int size();
容器中元素的数量。
boolean isEmpty();
容器是否为空。
boolean add(Object o);
增加元素到容器中。
boolean addAll(Collection c);
将容器c中所有元素增加到本容器。
boolean remove(Object o);
从容器中移除元素。
boolean removeAll(Collection c);
移除本容器和容器c中都包含的元素。
boolean retainAll(Collection c);
取本容器和容器c中都包含的元素,移除非交集元素。
boolean contains(Object o);
容器中是否包含该元素。
boolean containsAll(Collection c);
本容器是否包含c容器所有元素。
Iterator iterator();
获得迭代器,用于遍历所有元素。
Object[] toArray();
把容器中元素转化成Object数组。
代码演示
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 package com.leo.unit1;import java.util.ArrayList;import java.util.Collection;public class Demo2Collection { public static void main (String[] args) { Collection c1 = new ArrayList (); System.out.println("添加前:isEmpty:" + c1.isEmpty()); c1.add("迪丽热巴" ); c1.add("古力娜扎" ); c1.add("马尔扎哈" ); System.out.println("c1:" +c1); System.out.println("size:" + c1.size()); System.out.println("添加后:isEmpty:" + c1.isEmpty()); Collection c2 = new ArrayList (); c2.add("阿里巴巴" ); c2.add("真皮沙发" ); c2.add("阿拉斯加" ); c2.add("萨瓦迪卡" ); System.out.println("c2:" +c2); c1.addAll(c2); System.out.println("addAll:" + c1); c1.remove("马尔扎哈" ); System.out.println("remove后:" + c1); Collection c3 = new ArrayList (); c3.add("古力娜扎" ); c3.add("阿里巴巴" ); c1.removeAll(c3); System.out.println("removeAll后:" + c1); Collection c4 = new ArrayList (); c4.add("迪丽热巴" ); c4.add("真皮沙发" ); c4.add("雷哥" ); c1.retainAll(c4); System.out.println("retainAll之后:" + c1); System.out.println(c1.contains("迪丽热巴" )); System.out.println(c4.containsAll(c1)); System.out.println("======" ); Object[] arr = c1.toArray(); for (Object o : arr) { System.out.println(o); } } }
List集合 List接口简介 List集合是一个有序的、可以重复、可以为null 的集合,有时候也可以称之为序列。
有序:有序指的不是有顺序,而是有序号。指的是每个元素都有索引标记,可以根据索引访问这些元素
可重复:指List中可以加入重复元素,判断是否重复的标准是调用 equals 方法
List接口是Collection的子接口,除了拥有Collection中的方法外,还有一些自己特有的方法
*方法名* *说明*
void add(int index, Object obj);
在指定位置插入元素。
boolean addAll(int index, Collection c);
在指定位置增加一组元素
Object set(int index, Object element);
修改指定位置的元素。
Object get(int index);
返回指定位置的元素。
boolean remove(int index);
删除指定位置的元素,后面元素通通前移一位。
int indexOf(Object o);
返回第一个匹配元素的索引。如果没有该元素,返回-1。
int lastIndexOf(Object o);
返回最后一个匹配元素的索引。如果没有该元素,返回-1。
List subList(int fromIndex, int toIndex);
取出集合中的子集合。
ListIterator listIterator();
为ListIterator接口实例化。
ArrayList是List接口最常见的实现类,除此之外还有LinkedList和Vector
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 package com.leo.list;import java.util.ArrayList;import java.util.List;public class Demo1List { public static void main (String[] args) { List list = new ArrayList (); list.add("迪丽热巴" ); list.add("古力娜扎" ); list.add("真皮沙发" ); list.add("阿拉斯加" ); System.out.println(list); list.add(2 , "阿里巴巴" ); System.out.println(list); list.set(2 , "马尔扎哈" ); System.out.println(list); Object o = list.get(2 ); System.out.println(o); list.remove(2 ); System.out.println(list); System.out.println(list.indexOf("真皮沙发" )); List subList = list.subList(1 , 3 ); System.out.println(subList); } }
ArrayList类源码分析 ArrayList介绍 ArrayList是基于数组实现的,并且底层维护的数组容量可以自动增长
ArrayList特点是:查询效率高,增删效率低,线程不安全
成员变量和静态变量 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 private static final int DEFAULT_CAPACITY = 10 ; private static final Object[] EMPTY_ELEMENTDATA = {}; private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {}; transient Object[] elementData; private int size;
构造方法分析 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public ArrayList () { this .elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA; } public ArrayList (int initialCapacity) { if (initialCapacity > 0 ) { this .elementData = new Object [initialCapacity]; } else if (initialCapacity == 0 ) { this .elementData = EMPTY_ELEMENTDATA; } else { throw new IllegalArgumentException ("Illegal Capacity: " + initialCapacity); } }
添加方法分析 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 public boolean add (E e) { modCount++; add(e, elementData, size); return true ; } private void add (E e, Object[] elementData, int s) { if (s == elementData.length) elementData = grow(); elementData[s] = e; size = s + 1 ; } private Object[] grow() { return grow(size + 1 ); } private Object[] grow(int minCapacity) { int oldCapacity = elementData.length; if (oldCapacity > 0 || elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA) { int newCapacity = ArraysSupport.newLength(oldCapacity, minCapacity - oldCapacity, oldCapacity >> 1 ); return elementData = Arrays.copyOf(elementData, newCapacity); } else { return elementData = new Object [Math.max(DEFAULT_CAPACITY, minCapacity)]; } } public static int newLength (int oldLength, int minGrowth, int prefGrowth) { int prefLength = oldLength + Math.max(minGrowth, prefGrowth); if (0 < prefLength && prefLength <= SOFT_MAX_ARRAY_LENGTH) { return prefLength; } else { return hugeLength(oldLength, minGrowth); } } private static int hugeLength (int oldLength, int minGrowth) { int minLength = oldLength + minGrowth; if (minLength < 0 ) { throw new OutOfMemoryError ( "Required array length " + oldLength + " + " + minGrowth + " is too large" ); } else if (minLength <= SOFT_MAX_ARRAY_LENGTH) { return SOFT_MAX_ARRAY_LENGTH; } else { return minLength; } }
记一个结论:数组扩容时,会扩容成原本的1.5倍,如果计算出的扩容长度超出了系统最大能支持的数组长度,就以最大值为准
获取元素方法 get方法逻辑非常简单,就像是数组操作一样
1 2 3 4 5 6 7 8 9 10 11 public E get (int index) { Objects.checkIndex(index, size); return elementData(index); } E elementData (int index) { return (E) elementData[index]; }
修改元素方法 修改元素方法就是修改指定索引位置的元素,也很简单
1 2 3 4 5 6 7 8 9 10 public E set (int index, E element) { Objects.checkIndex(index, size); E oldValue = elementData(index); elementData[index] = element; return oldValue; }
插入方法分析 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public void add (int index, E element) { rangeCheckForAdd(index); modCount++; final int s; Object[] elementData; if ((s = size) == (elementData = this .elementData).length) elementData = grow(); System.arraycopy(elementData, index, elementData, index + 1 , s - index); elementData[index] = element; size = s + 1 ; }
删除方法分析 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public E remove (int index) { Objects.checkIndex(index, size); final Object[] es = elementData; E oldValue = (E) es[index]; fastRemove(es, index); return oldValue; } private void fastRemove (Object[] es, int i) { modCount++; final int newSize; if ((newSize = size - 1 ) > i) System.arraycopy(es, i + 1 , es, i, newSize - i); es[size = newSize] = null ; }
手写ArrayList 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 package com.leo.list;public class LeoArrayList { private Object[] elementData; private int size; public LeoArrayList () { elementData = new Object [0 ]; } public void add (Object e) { if (elementData.length == size) { int newLength = (int ) (elementData.length * 1.5 ); newLength = Math.max(newLength, 2 ); Object[] newElementData = new Object [newLength]; System.arraycopy(elementData, 0 , newElementData, 0 , elementData.length); elementData = newElementData; } elementData[size] = e; size++; } public Object get (int index) { checkIndexRange(index); return elementData[index]; } public Object remove (int index) { checkIndexRange(index); Object oldValue = elementData[index]; int newSize = size - 1 ; if (newSize > index) { System.arraycopy(elementData, index + 1 , elementData, index, size - index - 1 ); } elementData[newSize] = null ; size = newSize; return oldValue; } private void checkIndexRange (int index) { if (index >= size) { throw new IndexOutOfBoundsException ("索引越界:" + index); } } public static void main (String[] args) { LeoArrayList list = new LeoArrayList (); list.add("迪丽热巴" ); list.add("古力娜扎" ); list.add("马尔扎哈" ); list.add("真皮沙发" ); list.add("阿拉斯加" ); list.remove(2 ); list.remove(2 ); System.out.println(list.get(2 )); } }
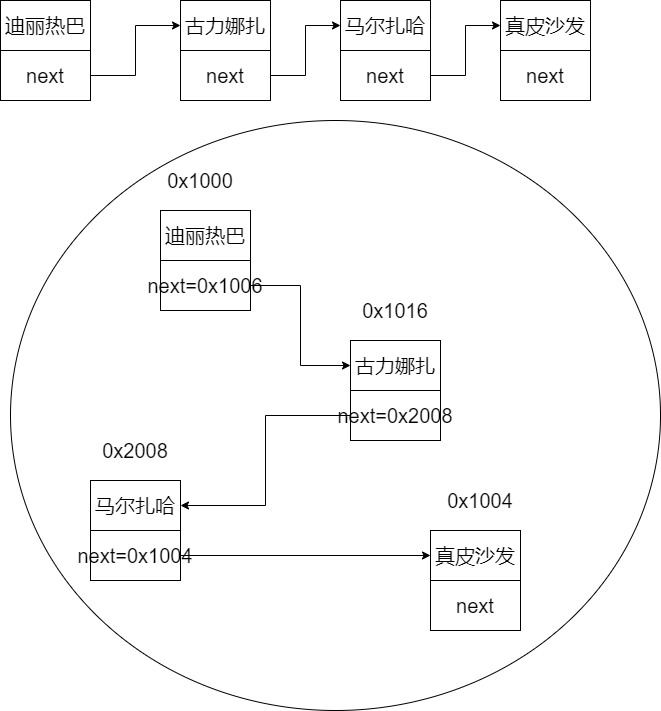
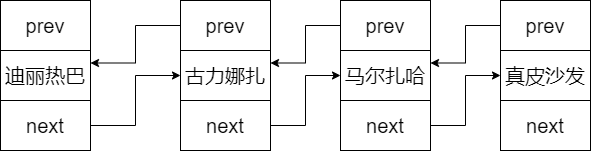
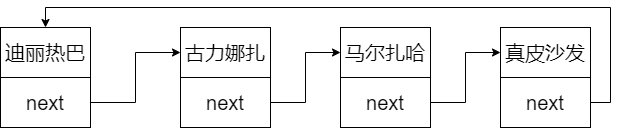
链式存储结构 单链表 单链表采用的是链式存储结构,每一个节点都是个对象,这个对象有两个属性,一个属性用来存储当前节点的数据,一个属性用来记录下一个位置的引用
链表的特点:查询性能低,添加和删除性能高
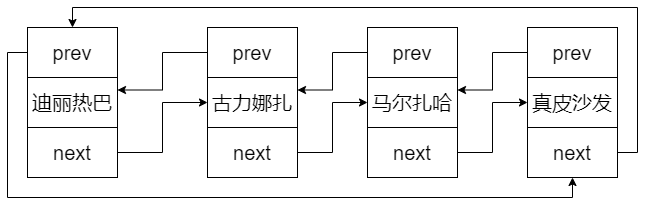
双链表 单链表存在一个弊端:它只能满足从首结点遍历到尾结点的操作,想从尾结点遍历到首结点则无法实现
双链表则是在链表的每一个节点上。再加一个引用,记录这个节点是上一个节点,这样就可以实现从头到尾和从尾到头两种方式的遍历。这样可以根据要查询的索引位置决定遍历的方向,从而提高性能
环形链表 环形链表则分为环形单链表和环形双链表两种。
LinkedList源码分析 简单使用 LinkedList的使用与ArrayList几乎没有区别,只是它内部增加了一些新的方法
*方法名* *说明*
void addFirst(Object obj);
将指定元素插入该双向队列的开头
void addLast(Object obj);
将指定元素插入该双向队列的末尾
Object getFirst();
获取,但不删除双向队列的第一个元素
Object getLast();
获取,但不删除双向队列的最后一个元素
boolean offerFirst(Object obj);
将指定的元素插入该双向队列的开头
boolean offerLast(Object obj);
将指定的元素插入该双向队列的末尾
Object peekFirst();
获取,但不删除该双向队列的第一个元素,如果些双向队列为空,则返回null
Object peekLast();
获取,但不删除该双向队列的最后一个元素,如果些双向队列为空,则返回null
Object pollFirst();
获取,并删除该双向队列的第一个元素,如果些双向队列为空,则返回null
Object pollLast();
获取,并删除该双向队列的最后一个元素,如果些双向队列为空,则返回null
Object pop();
弹出该双向队列所表示的栈中的第一个元素
void push(Object e)
将一个元素push进该双向队列所表示的栈中(头插入)
Object removeFirst()
获取,并删除该双向队列的第一个元素
Object removeFirstOccurrence(Object obj)
获取,并删除该双向队列的第一次出现的元素obj
Object removeLast()
获取,并删除该双向队列的最后一个元素
Object removeLastOccurrence(Object obj)
获取,并删除该双向队列的最后一次出现的元素obj
一般来说,上述方法使用频率偏低
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 package com.leo.list;import java.util.LinkedList;import java.util.List;public class Demo2LinkedList { public static void main (String[] args) { List list = new LinkedList (); list.add("迪丽热巴" ); list.add("古力娜扎" ); list.add("真皮沙发" ); list.add("阿拉斯加" ); System.out.println(list); list.add(2 , "阿里巴巴" ); System.out.println(list); list.set(2 , "马尔扎哈" ); System.out.println(list); Object o = list.get(2 ); System.out.println(o); list.remove(2 ); System.out.println(list); System.out.println(list.indexOf("真皮沙发" )); List subList = list.subList(1 , 3 ); System.out.println(subList); } }
ArrayList和LinkedList的使用基本没有区别,只是需要区分清楚二者的应用场景
ArrayList底层是用数组实现的,查询快,增删慢
LinkedList地层是用链表实现的,增删快,查询慢
成员变量和结点类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 transient int size = 0 ;transient Node<E> first;transient Node<E> last;private static class Node <E> { E item; Node<E> next; Node<E> prev; Node(Node<E> prev, E element, Node<E> next) { this .item = element; this .next = next; this .prev = prev; } }
添加方法分析 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public boolean add (E e) { linkLast(e); return true ; } void linkLast (E e) { final Node<E> l = last; final Node<E> newNode = new Node <>(l, e, null ); last = newNode; if (l == null ) first = newNode; else l.next = newNode; size++; modCount++; }
获取方法分析 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public E get (int index) { checkElementIndex(index); return node(index).item; } Node<E> node (int index) { if (index < (size >> 1 )) { Node<E> x = first; for (int i = 0 ; i < index; i++) x = x.next; return x; } else { Node<E> x = last; for (int i = size - 1 ; i > index; i--) x = x.prev; return x; } }
删除方法分析 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 public E remove (int index) { checkElementIndex(index); return unlink(node(index)); } E unlink (Node<E> x) { final E element = x.item; final Node<E> next = x.next; final Node<E> prev = x.prev; if (prev == null ) { first = next; } else { prev.next = next; x.prev = null ; } if (next == null ) { last = prev; } else { next.prev = prev; x.next = null ; } x.item = null ; size--; modCount++; return element; }
手写LinkedList 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 package com.leo.list;public class LeoLinkedList { private int size; private Node first; private Node last; public LeoLinkedList () { } public void add (Object e) { Node l = last; Node node = new Node (l, e, null ); if (last == null ) { first = node; }else { l.next = node; } last = node; size++; } public Object get (int index) { return node(index).item; } private Node node (int index) { Node x = first; for (int i = 0 ; i < index; i++) { x = x.next; } return x; } public Object remove (int index) { return unlink(node(index)); } private Object unlink (Node node) { Object item = node.item; Node prev = node.prev; Node next = node.next; if (prev == null ) { first = next; }else { prev.next = next; node.prev = null ; } if (next == null ) { last = prev; }else { next.prev = prev; node.next = null ; } node.item = null ; size--; return item; } private static class Node { Node prev; Object item; Node next; public Node (Node prev, Object item, Node next) { this .prev = prev; this .item = item; this .next = next; } } public static void main (String[] args) { LeoLinkedList list = new LeoLinkedList (); list.add("迪丽热巴" ); list.add("古力娜扎" ); list.add("马尔扎哈" ); list.add("真皮沙发" ); list.add("阿拉斯加" ); list.remove(2 ); list.remove(2 ); System.out.println(list.get(2 )); } }
Vector类 Vector的使用方式与ArrayList几乎一模一样,底层也采用了数组结构,很多情况下可以互用。
Vector底层的很多方法都加了同步检查,因此是线程安全的,但是效率偏低。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 package com.leo.list;import java.util.List;import java.util.Vector;public class Demo3Vector { public static void main (String[] args) { List list = new Vector (); list.add("迪丽热巴" ); list.add("古力娜扎" );; list.add("马尔扎哈" ); list.add("真皮沙发" ); list.add("阿拉斯加" ); System.out.println(list); list.remove(2 ); System.out.println(list); System.out.println(list.get(2 )); } }
当存在线程安全问题时,使用Vector
否则,如果查找和修改较多,可以使用ArrayList
如果增删较多,可以使用LinkedList
如果在使用ArrayList时,能够预先知道集合中需要存储多少元素,从而创建出一个在使用过程中不会出现扩容的集合,此时可以使用ArrayList
泛型 泛型介绍 泛型的作用是帮我们建立类型安全的集合,在使用了泛型的集合中,不必进行强制类型转换
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 package com.leo.generic;import java.util.ArrayList;import java.util.List;public class Demo1 { public static void main (String[] args) { List list = new ArrayList (); list.add("迪丽热巴" ); list.add("古力娜扎" ); list.add(123 ); list.add(true ); list.add('c' ); list.remove(0 ); Integer o = (Integer) list.get(2 ); System.out.println(o); } }
上面的程序在使用过程中,就非常容易出现类型转换异常
泛型的引入 在JDK5之前,我们使用集合时只能通过代码规范一类的约束来要求开发者谨慎往集合中存储数据,这种情况下取出集合中的元素时就必须要进行强制类型转换,但由于集合中可以存储任何类型,就很有可能出现类型转换异常。
为了解决这种问题,就引入了泛型机制,引入了泛型机制之后,集合中就可以只存储指定类型的数据,从而省去强制类型转换的过程,避免了类型转换异常
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 package com.leo.generic;import java.util.ArrayList;import java.util.List;public class Demo2 { public static void main (String[] args) { List<String> list = new ArrayList <>(); list.add("迪丽热巴" ); list.add("古力娜扎" ); String s = list.get(1 ); System.out.println(s); } }
泛型的本质就是“数据类型的参数化”,我们可以把泛型看成一种参数,给了泛型之后,就是告诉编译器,这个集合只能存储这种类型的数据,如果类型不匹配,编译期就会报错。
泛型只在编译时生效,程序运行时会把泛型擦除
泛型的使用 含有泛型的类 语法
E即是泛型,这个E可以理解成“假设”的一个数据类型,下面的代码中都可以将它视为一个数据类型进行使用,在new对象时,给的泛型是什么数据类型,那么在编译期就会把E视为什么数据类型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 package com.leo.generic.domain;public class Box <E> { private E obj; public E getObj () { return obj; } public void setObj (E obj) { this .obj = obj; } }
泛型在使用的过程中,要求必须得是引用数据类型,如果想存储基本数据类型,泛型应该指定为它们的包装类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 package com.leo.generic;import com.leo.generic.domain.Box;public class Demo3 { public static void main (String[] args) { Box<Integer> box1 = new Box <>(); box1.setObj(1 ); System.out.println(box1.getObj()); Box<String> box2 = new Box <>(); box2.setObj("HelloWorld" ); System.out.println(box2.getObj()); } }
注意:静态方法不能使用定义在类上的泛型
含有泛型的方法 语法
1 2 3 修饰符 <T> 返回值类型 方法名(参数列表) { 方法体 }
在方法上定义了泛型之后,整个方法都可以使用这个泛型,包括返回值类型、参数列表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 package com.leo.generic.domain;public class Box2 { public <T> T method (T obj) { System.out.println("成员方法:" +obj); return obj; } public static <T> T method2 (T obj) { System.out.println("静态方法:" + obj); return obj; } }
代码演示
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 package com.leo.generic;import com.leo.generic.domain.Box2;public class Demo4 { public static void main (String[] args) { Box2 box = new Box2 (); String s1 = box.method("HelloWorld" ); System.out.println(s1); System.out.println("==============" ); Integer num = Box2.method2(123 ); System.out.println(num); } }
含有泛型的接口 语法
1 2 3 修饰符 interface 接口名<E> { }
代码演示
1 2 3 4 5 6 package com.leo.generic.domain;public interface MyInterface <E> { void method (E e) ; }
由于接口不能直接创建对象,必须要有一个类实现它,或者有一个接口继承它
发生在继承关系之间的泛型有两种情况
继承之后就确定泛型的类型
1 2 3 4 5 6 7 8 9 package com.leo.generic.domain;public class Impl1 implements MyInterface <String>{ @Override public void method (String s) { System.out.println(s); } }
这种情况下在继承/实现时就可以直接指定泛型类型,此时重写方法中如果使用到了泛型,在代码中就会被替换成特定的类型,如果要创建这个类的对象,就不需要再去指定泛型类型
1 2 3 4 5 6 7 8 9 10 11 12 package com.leo.generic;import com.leo.generic.domain.Impl1;import com.leo.generic.domain.MyInterface;public class Demo5 { public static void main (String[] args) { Impl1 impl1 = new Impl1 (); impl1.method("HelloWorld" ); } }
如果子类也无法确定泛型,就给子类也设置泛型
1 2 3 4 5 6 7 8 9 package com.leo.generic.domain;public class Impl2 <E> implements MyInterface <E>{ @Override public void method (E e) { System.out.println(e); } }
此时如果重写或者实现对应的抽象方法,方法中使用到泛型的地方也是泛型
1 2 3 4 5 6 7 8 9 10 11 package com.leo.generic;import com.leo.generic.domain.Impl2;public class Demo6 { public static void main (String[] args) { Impl2<Double> impl2 = new Impl2 <>(); impl2.method(3.14 ); } }
泛型的通配符 有的时候在定义方法或者使用集合时,我们无法确定具体应该给什么数据类型,为了解决这个问题,可以使用泛型通配符
泛型通配符有三种形式:
无限定通配符,<?>
上限通配符,<? extends 类名>,限定参数类型只能是指定的类和他的子类
下限通配符,<? super 类名>,限定参数类型只能是指定的类和他的父类
注意:使用了泛型通配符之后,可以正常取值,但不能存值
无限定通配符
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 package com.leo.generic;import java.util.ArrayList;import java.util.List;public class Demo7 { public static void main (String[] args) { List<String> list1 = new ArrayList <>(); list1.add("HelloWorld" ); list1.add("迪丽热巴" ); printList(list1); List<Integer> list2 = new ArrayList <>(); list2.add(123 ); list2.add(234 ); printList(list2); } public static void printList (List<?> list) { System.out.println(list); } }
上限通配符
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 package com.leo.generic;import java.util.ArrayList;import java.util.List;public class Demo8 { public static void main (String[] args) { List<String> list1 = new ArrayList <>(); list1.add("迪丽热巴" ); list1.add("古力娜扎" ); printStrList(list1); List<StringBuilder> list2 = new ArrayList <>(); list2.add(new StringBuilder ("马尔扎哈" )); list2.add(new StringBuilder ("真皮沙发" )); printStrList(list2); } public static void printStrList (List<? extends CharSequence> list) { System.out.println(list); } }
下限通配符
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 package com.leo.generic;import com.leo.generic.domain.Impl1;import com.leo.generic.domain.Impl1Parent;import java.util.ArrayList;import java.util.List;public class Demo9 { public static void main (String[] args) { List<Impl1> list = new ArrayList <>(); list.add(new Impl1 ()); list.add(new Impl1 ()); showList(list); List<Impl1Parent> list1 = new ArrayList <>(); list1.add(new Impl1Parent ()); list1.add(new Impl1Parent ()); showList(list1); } public static void showList (List<? super Impl1> list) { System.out.println(list); } }
泛型类和泛型方法中使用通配符
在定义泛型方法和泛型类时,如果使用通配符,只需要在定义时指定,使用时不指定
1 2 3 4 5 6 7 8 9 10 11 package com.leo.generic;public class Demo10 { public static void main (String[] args) { showNum(123 ); } public static <T extends Number > void showNum (T t) { System.out.println(t.doubleValue()); } }
泛型方法中指定了泛型上限之后,就可以使用父类中定义的一些方法
下面是泛型类
1 2 3 4 5 6 7 8 package com.leo.generic.domain;public class MyList <E extends Number > { public void method (E e) { System.out.println(e); } }
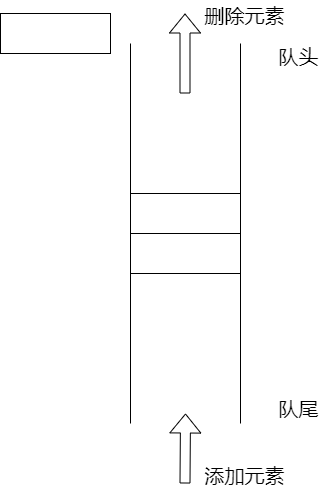
队列 队列的简介 队列是一种特殊的线性列表,它只允许在列表的前端(队头)进行删除操作,在列表的后端(队尾)进行插入操作,也存在双向队列,即队头和队尾都可以添加和删除
队列涉及的方法如下
*方法名* *描述*
boolean add(E e);
这两个方法都是在尾部添加元素add()会在长度不够时抛出异常; offer()则不会,只返回false
boolean offer(E e);
E element();
这两个方法都是查看头部元素 ,返回头部元素,但不改变队列element()会在没元素时抛出异常; peek()则返回null;
E peek();
E remove();
这两个方法都是删除头部元素,返回头部元素,并且从队列中删除remove()会在没元素时抛出异常; poll()返回null;
E poll();
boolean isEmpty();
判断队列是否为空,如果为空则返回true;否则返回false。
Queue接口是Java中队列的接口,最常见的一个实现类是LinkedList
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 package com.leo.queue;import java.util.LinkedList;import java.util.Queue;public class Demo1 { public static void main (String[] args) { Queue<String> queue = new LinkedList <>(); queue.add("迪丽热巴" ); queue.offer("古力娜扎" ); queue.add("马尔扎哈" ); queue.offer("真皮沙发" ); System.out.println(queue); System.out.println(queue.peek()); System.out.println(queue.element()); System.out.println(queue); while (!queue.isEmpty()) { System.out.println(queue.poll()); } } }
合理的使用队列,可以实现排队效果
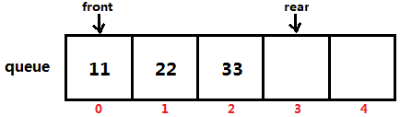
队列的实现(数组) 数组实现的队列是一个有界队列,因为数组在创建时必须要指定长度,所以这种方式实现的队列是有容量大小的。
创建一个数组之后,默认第0个元素既是队头也是队尾,每添加一个元素,都将队尾向后移动一位,每删一个元素,队头也向后移动一位,当队尾超过数组的容量之后,回归到数组第0个位置,队头也同理
但是这样会存在一个问题,即队列满和队列空时,front都与rear相同,那么我们的解决方案是,让数组其中一个位置不存储元素,即元素个数为数组长度-1时,就是队列满了。即:front==(rear+1)%数组长度时,队列满了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 package com.leo.queue;import java.util.Arrays;public class ArrayQueue <E> { private Object[] elementData; private int front; private int rear; public ArrayQueue () { this (10 ); } public ArrayQueue (int capacity) { this .elementData = new Object [capacity]; } public boolean offer (E element) { if (isFull()) { return false ; } this .elementData[rear] = element; rear++; if (rear == elementData.length) { rear = 0 ; } return true ; } public E peek () { return (E) elementData[front]; } public E poll () { if (isEmpty()) { return null ; } Object data = this .elementData[front]; this .elementData[front] = null ; front++; if (front == elementData.length) { front = 0 ; } return (E) data; } private boolean isEmpty () { return this .rear == this .front; } public int size () { if (this .rear >= this .front) { return this .rear - this .front; } return this .rear + elementData.length - this .front; } public boolean isFull () { return this .front == (this .rear+1 )%this .elementData.length; } }
测试类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 package com.leo.queue;public class Demo2 { public static void main (String[] args) { ArrayQueue<String> queue = new ArrayQueue <>(5 ); queue.offer("迪丽热巴" ); queue.offer("古力娜扎" ); queue.offer("马尔扎哈" ); queue.offer("真皮沙发" ); System.out.println(queue.poll()); System.out.println(queue.poll()); queue.offer("阿拉斯加" ); queue.offer("阿里巴巴" ); System.out.println(queue.poll()); System.out.println(queue.poll()); System.out.println(queue.poll()); System.out.println(queue.poll()); } }
队列的实现(链表) 链表实现队列就是一个非常简单的单链表,添加元素时追加到链表尾部,取出元素时从链表头部取出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 package com.leo.queue;public class LinkedQueue <E> { private Node<E> front; private Node<E> rear; private int size; public int size () { return size; } public void offer (E element) { Node<E> node = new Node <>(element, null ); if (rear == null ) { rear = node; front = node; }else { rear.next = node; rear = rear.next; } size++; } public E peek () { return front.data; } public E poll () { if (rear == null ) { return null ; } E data = front.data; front = front.next; size--; if (size == 0 ) { rear = null ; } return data; } private static class Node <E> { private E data; private Node<E> next; public Node (E data, Node<E> next) { this .data = data; this .next = next; } } }
测试类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 package com.leo.queue;public class Demo3 { public static void main (String[] args) { LinkedQueue<String> queue = new LinkedQueue <>(); queue.offer("迪丽热巴" ); queue.offer("古力娜扎" ); queue.offer("马尔扎哈" ); queue.offer("真皮沙发" ); System.out.println(queue.poll()); System.out.println(queue.poll()); queue.offer("阿拉斯加" ); queue.offer("阿里巴巴" ); System.out.println(queue.poll()); System.out.println(queue.poll()); System.out.println(queue.poll()); System.out.println(queue.poll()); } }
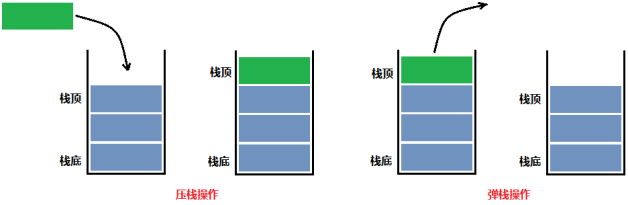
栈 栈的简介 栈是一种特殊的线性表,只能在栈的一端(栈顶)操作,先进来的元素会被压到栈底部,所以添加元素也称之为“压栈”,删除元素也是从栈顶出去,也叫作“出栈”或者“弹栈”。
先进后出,或者后进先出
*方法名* *描述*
void push(E e);
入栈,在头部添加元素,栈的空间可能是有限的,如果栈满了,会抛出异常。
E pop();
出栈,返回头部元素,并且从栈中删除,如果栈为空,会抛出异常。
E peek();
查看栈头部元素,不修改栈,如果栈为空,返回null。
boolean isEmpty();
判断栈是否为空,如果为空则返回true;否则返回false。
代码演示
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 package com.leo.stack;import java.util.Deque;import java.util.LinkedList;public class Demo1 { public static void main (String[] args) { Deque<String> deque = new LinkedList <>(); deque.push("迪丽热巴" ); deque.push("古力娜扎" ); deque.push("马尔扎哈" ); deque.push("真皮沙发" ); deque.push("阿拉斯加" ); System.out.println(deque); while (!deque.isEmpty()) { System.out.println(deque.pop()); } } }
栈的实现(数组) 数组实现栈结构非常简单,只需要一个栈顶指针,默认值是-1(因为没有数据时栈顶是不存在的),每向栈顶入栈一个元素,栈顶+1,每出栈一个元素,栈顶-1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 package com.leo.stack;public class ArrayStack <E> { private Object[] elementData; private int top = -1 ; public ArrayStack (int size) { this .elementData = new Object [size]; } public boolean push (E item) { if (top == elementData.length-1 ) { return false ; } top++; elementData[top] = item; return true ; } public E pop () { if (top == -1 ) { return null ; } E e = (E) elementData[top]; elementData[top] = null ; top--; return e; } }
测试代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 package com.leo.stack;public class Demo2 { public static void main (String[] args) { ArrayStack<String> stack = new ArrayStack <>(5 ); stack.push("迪丽热巴" ); stack.push("古力娜扎" ); stack.push("马尔扎哈" ); stack.push("真皮沙发" ); stack.push("阿拉斯加" ); System.out.println(stack.pop()); System.out.println(stack.pop()); System.out.println(stack.pop()); System.out.println(stack.pop()); System.out.println(stack.pop()); } }
栈的实现(链表) 使用单链表也可以实现栈结构,只不过以往单链表添加元素都是往链表的尾部添加,而栈则是往链表的头部添加
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 package com.leo.stack;public class LinkedStack <E> { private Node<E> top; private int size; public void push (E item) { Node<E> node = new Node <>(item, top); top = node; size++; } public E pop () { if (top == null ) { return null ; } E item = top.item; top = top.next; return item; } private static class Node <E> { private E item; private Node<E> next; public Node (E item, Node<E> next) { this .item = item; this .next = next; } } }
测试代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 package com.leo.stack;public class Demo3 { public static void main (String[] args) { LinkedStack<String> stack = new LinkedStack <>(); stack.push("迪丽热巴" ); stack.push("古力娜扎" ); stack.push("马尔扎哈" ); stack.push("真皮沙发" ); stack.push("阿拉斯加" ); System.out.println(stack.pop()); System.out.println(stack.pop()); System.out.println(stack.pop()); System.out.println(stack.pop()); System.out.println(stack.pop()); } }
迭代器 List的遍历方式 List的遍历方式有三种:普通for循环、增强for循环、迭代器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 package com.leo.iterator;import java.util.ArrayList;import java.util.List;public class Demo1 { public static void main (String[] args) { List<String> list = new ArrayList <>(); list.add("迪丽热巴" ); list.add("古力娜扎" ); list.add("真皮沙发" ); list.add("阿拉斯加" ); for (int i = 0 ; i < list.size(); i++) { System.out.println(list.get(i)); } for (String s : list) { System.out.println(s); } } }
迭代器的存在,是为了让Java中每一种集合都可以使用一种通用的方式进行遍历。此外,使用传统的for循环来遍历集合只适用于取元素,不适用于增删元素
在增强for循环中删除集合中的元素,会抛出ConcurrentModificationException异常
普通for循环不会存在这种问题,但是需要对索引进行计算,因为只要元素发生更改,索引和集合长度会发生改变
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 package com.leo.iterator;import java.util.ArrayList;import java.util.List;public class Demo2 { public static void main (String[] args) { List<String> list = new ArrayList <>(); list.add("迪丽热巴" ); list.add("古力娜扎" ); list.add("刘玄德" ); list.add("雷哥" ); list.add("稽哥" ); list.add("东风雪铁龙" ); for (int i = 0 ; i < list.size(); i++) { if (list.get(i).length() <= 3 ) { list.remove(i); i--; } } System.out.println(list); } }
Iterator类详解 for循环只可以对集合进行遍历,但不能在遍历的过程中修改集合中元素的个数,一旦修改,就会抛出并发修改异常。迭代器的存在就是为了解决这种问题的。
此外,Java中有多种集合,它们存储元素时采取的存储方式不同,内部的机制也不同,不同的集合遍历方式可能会不一样,因此Java中提供的迭代器,为的就是提供一种通用的遍历方式,让每一个集合都有相同的遍历方式。
*方法名* *描述*
boolean hasNext();
判断集合中是否有下一个元素可以迭代,如果有,则返回 true。
Object next();
返回迭代的下一个元素,并把指针向后移动一位。
void remove();
将迭代器当前返回的元素删除(可选操作)。
迭代器的使用逻辑很简单,使用while循环,只要hasNext方法结果为true,就继续遍历,遍历的过程中, 使用next方法取出元素即可,如果这个过程中想删除元素,就调用remove方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 package com.leo.iterator;import java.util.ArrayList;import java.util.Iterator;import java.util.List;public class Demo3 { public static void main (String[] args) { List<String> list = new ArrayList <>(); list.add("迪丽热巴" ); list.add("古力娜扎" ); list.add("刘玄德" ); list.add("雷哥" ); list.add("稽哥" ); list.add("东风雪铁龙" ); Iterator<String> iterator = list.iterator(); while (iterator.hasNext()) { String next = iterator.next(); if (next.length() <= 3 ) { iterator.remove(); } } System.out.println(list); } }
注意:遍历的过程中如果想改变集合中元素的个数,一定要使用迭代器的remove方法,不能使用集合自带的remove方法,否则同样会抛出并发修改异常。
自定义集合迭代器 只要让集合实现Iterable接口,重写iterator方法,再提供一个自定义的迭代器类,即可为自定义的集合提供一种通用的迭代方式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 package com.leo.iterator;import java.util.Iterator;public class MyList implements Iterable <Object> { private Object[] elementData = {"a" , "b" , "c" , "d" , "e" }; private int size = 5 ; public Object get (int index) { return elementData[index]; } @Override public Iterator<Object> iterator () { return new MyIterator (); } private class MyIterator implements Iterator <Object> { private int cursor; @Override public boolean hasNext () { return cursor != size; } @Override public Object next () { Object value = get(cursor); cursor++; return value; } } }
代码测试
1 2 3 4 5 6 7 8 9 10 11 12 13 14 package com.leo.iterator;import java.util.Iterator;public class Demo4 { public static void main (String[] args) { MyList list = new MyList (); Iterator<Object> iterator = list.iterator(); while (iterator.hasNext()) { System.out.println(iterator.next()); } } }
ListIterator类 前面使用的Iterator类存在一个问题:只能删除元素,不能添加元素,如果想在迭代的过程中向集合中添加元素,就需要使用ListIterator类
*方法名* *描述*
boolean hasNext();
以正向遍历列表时,判断迭代器后面是否还有元素。
Object next();
返回列表中ListIterator指向位置后面的元素。
boolean hasPrevious();
以逆向遍历列表,判断迭代器前面是否还有元素。
Object previous();
返回列表中ListIterator指向位置前面的元素。
void remove();
从列表中删除next()或previous()返回的最后一个元素。
void set(Object e);
从列表中将next()或previous()返回的元素更改为指定元素。
void add(Object e);
将指定的元素插入列表,插入位置为迭代器当前位置之前。
代码演示
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 package com.leo.iterator;import java.util.ArrayList;import java.util.List;import java.util.ListIterator;public class Demo5 { public static void main (String[] args) { List<String> list = new ArrayList <>(); list.add("迪丽热巴" ); list.add("古力娜扎" ); list.add("刘玄德" ); list.add("雷哥" ); list.add("稽哥" ); list.add("东风雪铁龙" ); ListIterator<String> iterator = list.listIterator(); while (iterator.hasNext()) { String next = iterator.next(); if (next.length() >= 4 ) { iterator.add("哈哈" ); } } System.out.println(list); } }
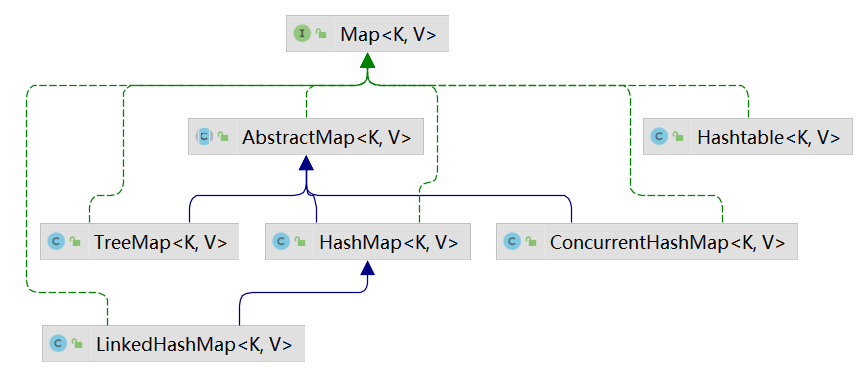
Map集合 Map集合介绍 现实生活中,我们经常需要成对 的存储某些信息,比如一个身份证号对应一个人,一个手机号对应一个微信,这就是一种成对关系
Map集合就是用来存储这种键(key)值(value)对 形式的数据的,使用key去对应value,所以一般情况下要求key不能重复
Map接口常见的实现类有:HashMap、LinkedHashMap、HashTable、ConcurrentHashMap、TreeMap、Properties
Map常用方法
*Map接口中定义的方法*
Object put(Object key, Object value);
存放键值对。
Object get(Object key);
通过键对象查找得到值对象。
Object remove(Object key);
删除键对象对应的键值对。
boolean containsKey(Object key);
Map容器中是否包含键对象对应的键值对。
boolean containsValue(Object value);
Map容器中是否包含值对象对应的键值对。
Collection values();
获取集合中所有的值
int size();
获取包含键值对的数量。
boolean isEmpty();
判断Map是否为空。
void clear();
清空本map对象所有键值对。
代码演示
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 package com.leo.map;import java.util.Collection;import java.util.HashMap;import java.util.Map;public class Demo1 { public static void main (String[] args) { Map<Integer, String> map = new HashMap <>(); map.put(11 , "迪丽热巴" ); map.put(22 , "古力娜扎" ); map.put(33 , "马尔扎哈" ); map.put(44 , "真皮沙发" ); System.out.println(map.get(33 )); map.remove(44 ); System.out.println(map.get(44 )); System.out.println(map.size()); map.put(33 , "阿拉斯加" ); System.out.println(map.get(33 )); System.out.println(map.size()); System.out.println(map.containsKey(33 )); System.out.println(map.containsValue("阿里巴巴" )); Collection<String> values = map.values(); System.out.println(values); } }
Map的遍历 Map集合存储结构比较特殊,内部是没有迭代器的,我们可以使用其他的遍历方式
keySet方法
keySet方法的作用是获取Map中所有的key,封装成一个Set集合,再遍历这个集合,遍历的过程中使用map.get方法根据key获取值,即可完成遍历
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 package com.leo.map;import java.util.HashMap;import java.util.Iterator;import java.util.Map;import java.util.Set;public class Demo2 { public static void main (String[] args) { Map<Integer, String> map = new HashMap <>(); map.put(11 , "迪丽热巴" ); map.put(22 , "古力娜扎" ); map.put(33 , "马尔扎哈" ); map.put(44 , "真皮沙发" ); Set<Integer> keys = map.keySet(); for (Integer key : keys) { System.out.println(key+":" +map.get(key)); } } }
这里我们发现,数据存储的顺序与遍历的顺序不一致,这是HashMap底层的一个机制,HashMap无法保证元素存取的顺序
entrySet方法(推荐使用)
entrySet方法也是获取到一个Set集合,这个set集合中存储的是一个Entry对象,Entry对象中就保存了键值对信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 package com.leo.map;import java.util.HashMap;import java.util.Map;import java.util.Set;public class Demo3 { public static void main (String[] args) { Map<Integer, String> map = new HashMap <>(); map.put(11 , "迪丽热巴" ); map.put(22 , "古力娜扎" ); map.put(33 , "马尔扎哈" ); map.put(44 , "真皮沙发" ); Set<Map.Entry<Integer, String>> entries = map.entrySet(); for (Map.Entry<Integer, String> entry : entries) { System.out.println(entry.getKey()+":" +entry.getValue()); } } }
我们推荐使用entrySet方法进行遍历,因为keySet方法遍历的性能比较差
Map的key判断是否重复 Map集合的key是不可以重复的,这就需要有一个判断依据,HashMap中的判断依据是equals和hashCode
下面自定义一个Student类,作为key
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 package com.leo.map;import java.util.Objects;public class Student { private String name; private String code; public Student (String name, String code) { this .name = name; this .code = code; } @Override public boolean equals (Object o) { if (this == o) return true ; if (o == null || getClass() != o.getClass()) return false ; Student student = (Student) o; return code.equals(student.code); } @Override public int hashCode () { return Objects.hash(code); } public String getName () { return name; } public void setName (String name) { this .name = name; } public String getCode () { return code; } public void setCode (String code) { this .code = code; } @Override public String toString () { return "Student{" + "name='" + name + '\'' + ", code='" + code + '\'' + '}' ; } } package com.leo.map;import java.util.HashMap;import java.util.Map;public class Demo4 { public static void main (String[] args) { Map<Student, String> map = new HashMap <>(); map.put(new Student ("张三" , "10000" ), "哈哈" ); map.put(new Student ("李四" , "10086" ), "哈哈" ); map.put(new Student ("张三丰" , "10000" ), "呵呵" ); for (Map.Entry<Student, String> entry : map.entrySet()) { System.out.println(entry.getKey()+":" +entry.getValue()); } } }
我们发现,在上面的代码中,code相同就会被认为是重复的key,此时不会作为新的元素进行添加,而是替换value。
注意:替换只会替换value,key不会替换,因为HashMap认为这两个key是完全相同的key,没有替换的必要,白白耗费性能,因此不会替换key
事实上,containsKey、containsValue底层也是使用equals方法进行判断的,List集合的contains方法也是使用equals方法进行判断的。
HashMap实现原理(重点) 实现原理描述 HashMap底层采用 数组+链表+红黑树(JDK8引入) 的结构实现的。HashMap底层维护了一个数组,这个数组也称之为 Hash桶 ,数组的每一个元素又同时是一个链表。数组的 默认长度是16 ,可以扩容
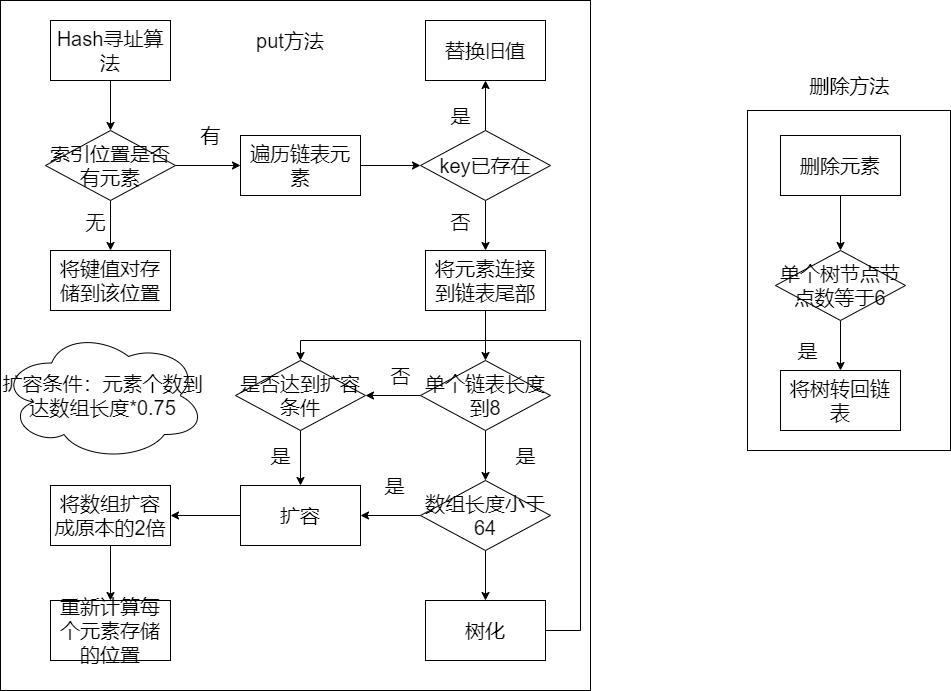
存储元素 HashMap的put方法实现逻辑很复杂。当有一个键值对需要存储到HashMap中时,做了以下的逻辑操作
首先,使用 hash寻址算法 对key进行一系列的计算,计算出的结果就是key需要存储在数组中的索引位置,计算公式:key.hashCode % 数组长度 。计算出的余数,就是元素需要存储到数组的哪个位置。这么做的目的是让所有的元素均匀的分布在数组中,为的是让链表不要太长。
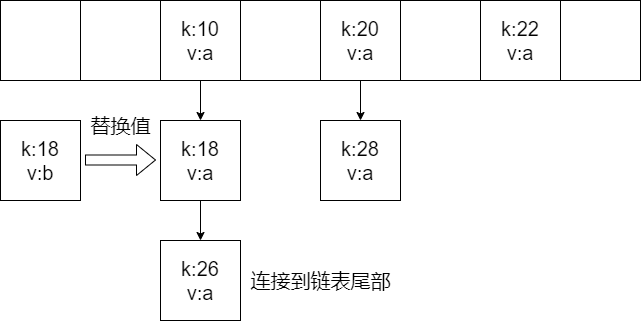
当计算出键值对需要存储的位置之后,会首先判断这个位置是否已经存储了元素
如果没有存储元素,直接将该键值对存储到这个索引位置。
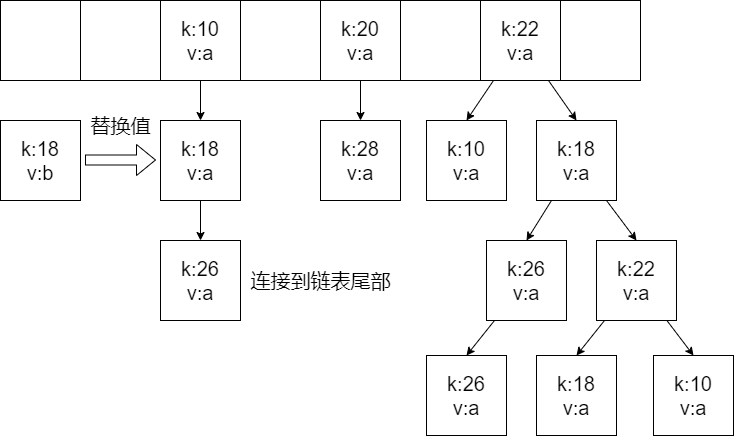
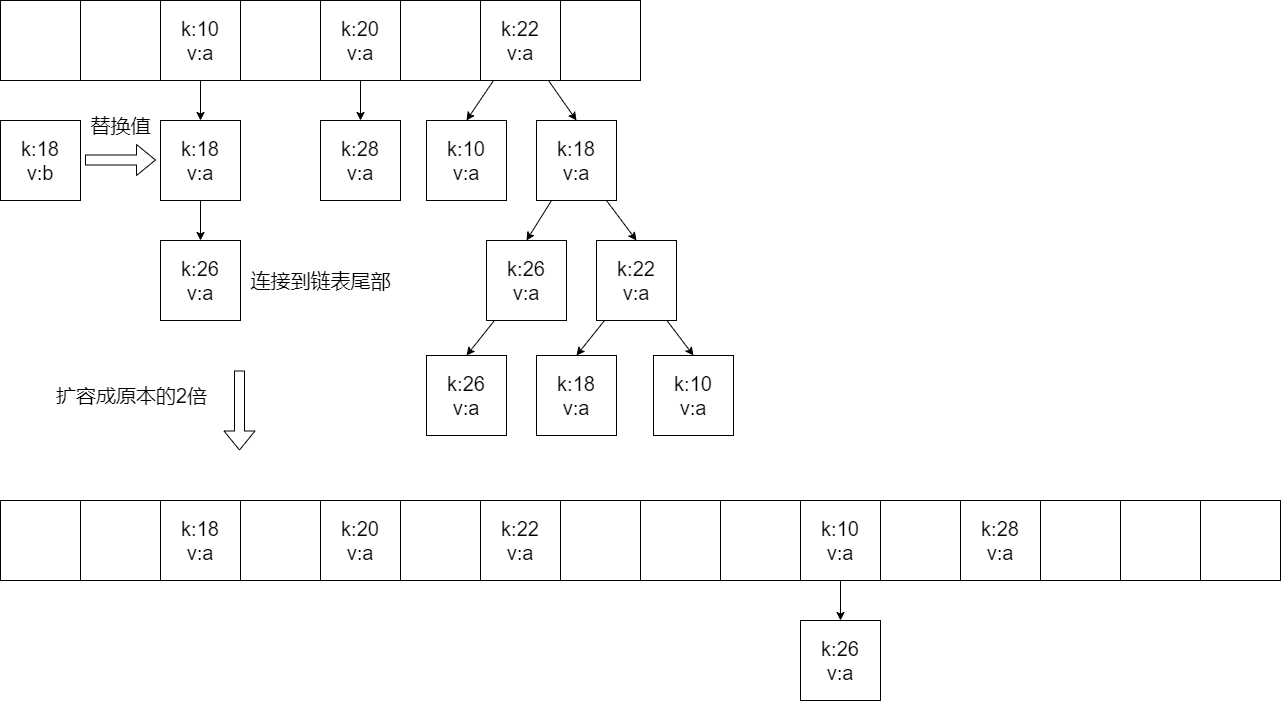
如果有元素,就遍历当前位置的这条链表,如果key已经存在,就替换旧值,如果不存在,就把元素连接到链表 尾部
扩容与树化 HashMap底层使用到了链表,当元素过多时,链表可能就会很长,此时影响了查询效率,因此HashMap底层会有一些机制,让链表不会太长,这个机制就是 扩容和树化
树化
当某个链表长度到8时,就会面临着扩容或者树化
如果数组长度小于64,就对数组进行扩容,扩容成原来的2倍
如果数组长度超过64,就会将当前链表转换成红黑树
在删除的过程中,如果某个红黑树的节点数到了6,就会将红黑树重新转换回链表
扩容
HashMap底层也有扩容操作。除了上面的情况外,当元素个数到达数组长度*0.75(加载因子) 时,也会对数组进行扩容,扩容到原来的2倍。
扩容之后,会将hashmap中所有的元素重新进行hash寻址计算,计算出在新数组中应当存储的位置 。
查询方法 查询方法非常简单,根据key查询value,先使用hash寻址算法,计算出这个key应该从哪个链表中查询,之后,遍历链表,比较key是否相同,如果key存在,返回value,如果不存在,返回null
删除方法 删除方法同样也很简单,首先根据key使用hash寻址算法,计算出这个key应该在哪个链表中删除,之后,遍历链表,比较key是否存在,如果存在,删除这个链表节点
源码分析 成员变量和静态变量 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 static final int DEFAULT_INITIAL_CAPACITY = 1 << 4 ; static final int MAXIMUM_CAPACITY = 1 << 30 ; static final float DEFAULT_LOAD_FACTOR = 0.75f ; static final int TREEIFY_THRESHOLD = 8 ; static final int UNTREEIFY_THRESHOLD = 6 ; static final int MIN_TREEIFY_CAPACITY = 64 ; transient Node<K,V>[] table; transient Set<Map.Entry<K,V>> entrySet; transient int size; transient int modCount; int threshold; final float loadFactor;
节点类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 static class Node <K,V> implements Map .Entry<K,V> { final int hash; final K key; V value; Node<K,V> next; Node(int hash, K key, V value, Node<K,V> next) { this .hash = hash; this .key = key; this .value = value; this .next = next; } public final K getKey () { return key; } public final V getValue () { return value; } public final String toString () { return key + "=" + value; } public final int hashCode () { return Objects.hashCode(key) ^ Objects.hashCode(value); } public final V setValue (V newValue) { V oldValue = value; value = newValue; return oldValue; } public final boolean equals (Object o) { if (o == this ) return true ; return o instanceof Map.Entry<?, ?> e && Objects.equals(key, e.getKey()) && Objects.equals(value, e.getValue()); } }
构造方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 public HashMap (int initialCapacity, float loadFactor) { if (initialCapacity < 0 ) throw new IllegalArgumentException ("Illegal initial capacity: " + initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY)、 initialCapacity = MAXIMUM_CAPACITY; if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException ("Illegal load factor: " + loadFactor); this .loadFactor = loadFactor; this .threshold = tableSizeFor(initialCapacity); } public HashMap (int initialCapacity) { this (initialCapacity, DEFAULT_LOAD_FACTOR); } public HashMap () { this .loadFactor = DEFAULT_LOAD_FACTOR; }
put方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 public V put (K key, V value) { return putVal(hash(key), key, value, false , true ); } final V putVal (int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; if ((tab = table) == null || (n = tab.length) == 0 ) n = (tab = resize()).length; if ((p = tab[i = (n - 1 ) & hash]) == null ) tab[i] = newNode(hash, key, value, null ); else { Node<K,V> e; K k; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this , tab, hash, key, value); else { for (int binCount = 0 ; ; ++binCount) { if ((e = p.next) == null ) { p.next = newNode(hash, key, value, null ); if (binCount >= TREEIFY_THRESHOLD - 1 ) treeifyBin(tab, hash); break ; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break ; p = e; } } if (e != null ) { V oldValue = e.value; if (!onlyIfAbsent || oldValue == null ) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; if (++size > threshold) resize(); afterNodeInsertion(evict); return null ; }
上面就分析完了put方法,留下来了几个问题:hash寻址算法,扩容
hash寻址算法 前面分析原理时,描述的hash寻址算法是 hash值 % 数组长度 ,但是阅读源码发现,源码中计算公式是 hash值 & (数组长度 - 1)
这是为什么?
事实上,这两种计算的计算结果是相同的(前提是数组长度为2的n次幂) ,因为位运算的运算性能比普通的四则运算要高很多,这么做是为了提高性能。
扩容机制 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 final Node<K,V>[] resize() { Node<K,V>[] oldTab = table; int oldCap = (oldTab == null ) ? 0 : oldTab.length; int oldThr = threshold; int newCap, newThr = 0 ; if (oldCap > 0 ) { if (oldCap >= MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return oldTab; } else if ((newCap = oldCap << 1 ) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) newThr = oldThr << 1 ; } else if (oldThr > 0 ) newCap = oldThr; else { newCap = DEFAULT_INITIAL_CAPACITY; newThr = (int )(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); } if (newThr == 0 ) { float ft = (float )newCap * loadFactor; newThr = (newCap < MAXIMUM_CAPACITY && ft < (float )MAXIMUM_CAPACITY ? (int )ft : Integer.MAX_VALUE); } threshold = newThr; @SuppressWarnings({"rawtypes","unchecked"}) Node<K,V>[] newTab = (Node<K,V>[])new Node [newCap]; table = newTab; if (oldTab != null ) { for (int j = 0 ; j < oldCap; ++j) { Node<K,V> e; if ((e = oldTab[j]) != null ) { oldTab[j] = null ; if (e.next == null ) newTab[e.hash & (newCap - 1 )] = e; else if (e instanceof TreeNode) ((TreeNode<K,V>)e).split(this , newTab, j, oldCap); else { Node<K,V> loHead = null , loTail = null ; Node<K,V> hiHead = null , hiTail = null ; Node<K,V> next; do { next = e.next; if ((e.hash & oldCap) == 0 ) if (loTail == null ) loHead = e; else loTail.next = e; loTail = e; } else { if (hiTail == null ) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null ); if (loTail != null ) { loTail.next = null ; newTab[j] = loHead; } if (hiTail != null ) { hiTail.next = null ; newTab[j + oldCap] = hiHead; } } } } } return newTab; }
扩容过程中,对于元素的重新计算索引,内部有一个优化机制
HashMap会将新的数组从中间分开,分成 低位数组和高位数组
然后 hash & 旧数组容量
在分析一定的规律之后发现,重新计算索引位置时,原数组中的元素,要么在低位数组的原本位置,要么在高位数组的对应位置。这两个位置相差正好是旧数组容量,换句话说,是否需要移动到高位数组的对应位置,只与旧数组容量有关
我们发现,新数组使用hash寻址算法计算结果时,相对于旧数组,只多出一个1,换句话说,运算后的结果是否改变,只与这个1相关,因此只需要算这个位置的结果即可,如果该位置发生了变化,元素就存储到高为数组,否则,就存储到低位数组
get方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 public V get (Object key) { Node<K,V> e; return (e = getNode(key)) == null ? null : e.value; } final Node<K,V> getNode (Object key) { Node<K,V>[] tab; Node<K,V> first, e; int n, hash; K k; if ((tab = table) != null && (n = tab.length) > 0 && (first = tab[(n - 1 ) & (hash = hash(key))]) != null ) { if (first.hash == hash && ((k = first.key) == key || (key != null && key.equals(k)))) return first; if ((e = first.next) != null ) { if (first instanceof TreeNode) return ((TreeNode<K,V>)first).getTreeNode(hash, key); do { if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } while ((e = e.next) != null ); } } return null ; }
HashMap优化技巧
设置HashMap的容量为2的整数次幂
在能够预知HashMap存储多少元素时,创建HashMap给定一个不会发生扩容的容量(避免发生HashMap扩容)
在使用HashMap时一定要初始化容量
手写HashMap 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 package com.leo.map;public class LeoHashMap <K, V> { private static final int DEFAULT_INITIAL_CAPACITY = 8 ; private static final float DEFAULT_LOAD_FACTOR = 0.75f ; private Node<K, V>[] table; private int size; private float loadFactor; private int threshold; public LeoHashMap () { table = new Node [DEFAULT_INITIAL_CAPACITY]; loadFactor = DEFAULT_LOAD_FACTOR; threshold = (int ) (table.length * loadFactor); } public void put (K k, V v) { Node<K, V>[] tab = table; int index = getIndex(k); Node<K, V> e = tab[index]; if (e == null ) { tab[index] = new Node <>(k.hashCode(), k, v, null ); size++; }else { while (true ) { if (e.hash == k.hashCode() && e.k.equals(k)) { e.v = v; break ; } if (e.next == null ) { e.next = new Node <>(k.hashCode(), k, v, null ); size++; break ; } e = e.next; } } if (size > threshold) { resize(); } } private void resize () { Node<K, V>[] oldTab = this .table; int oldLength = oldTab.length; int oldThr = threshold; Node<K, V>[] newTab = new Node [oldLength * 2 ]; table = newTab; threshold = oldThr * 2 ; for (int i = 0 ; i < oldTab.length; i++) { Node<K, V> e = oldTab[i]; if (e == null ) { continue ; } if (e.next == null ) { newTab[getIndex(e.k)] = e; continue ; } Node<K, V> loHead = null , loTail = null ; Node<K, V> hiHead = null , hiTail = null ; while (true ) { if ((e.hash & oldLength) == 0 ) { if (loTail == null ) { loHead = e; }else { loTail.next = e; } loTail = e; }else { if (hiTail == null ) { hiHead = e; }else { hiTail.next = e; } hiTail = e; } e = e.next; if (e == null ) { break ; } } if (loHead != null ) { newTab[i] = loHead; } if (hiHead != null ) { newTab[i+oldLength] = hiHead; } } } public V get (K k) { Node<K, V>[] tab = this .table; int index = getIndex(k); Node<K, V> e = tab[index]; if (e == null ) { return null ; } while (true ) { if (e.hash == k.hashCode() && e.k.equals(k)) { return e.v; } e = e.next; if (e == null ) { break ; } } return null ; } public int getIndex (K k) { return k.hashCode() & (table.length - 1 ); } private static class Node <K, V> { int hash; final K k; V v; Node<K, V> next; public Node (int hash, K k, V v, Node<K, V> next) { this .hash = hash; this .k = k; this .v = v; this .next = next; } } }
LinkedHashMap HashMap不能保证存取顺序完全一致,如果想要保证存取顺序一致,可以使用LinkedHashMap。它的使用方式与HashMap完全一致
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 package com.leo.map;import java.util.HashMap;import java.util.LinkedHashMap;import java.util.Map;import java.util.Set;public class Demo6 { public static void main (String[] args) { Map<Integer, String> map = new LinkedHashMap <>(); map.put(11 , "迪丽热巴" ); map.put(22 , "古力娜扎" ); map.put(33 , "马尔扎哈" ); map.put(44 , "真皮沙发" ); Set<Map.Entry<Integer, String>> entries = map.entrySet(); for (Map.Entry<Integer, String> entry : entries) { System.out.println(entry.getKey()+":" +entry.getValue()); } } }
Hashtable Hashtable的使用与HashMap一模一样,底层的实现也很类似,不同之处在于Hashtable内部的一些方法加了同步锁,这意味着它是线程安全的。
如果不存在线程安全问题,就使用HashMap,否则使用Hashtable
ConcurrentHashMap Hashtable是一个非常古老的类,性能很低,现在的开发中已经不再使用这个类了,取而代之的是ConcurrentHashMap。这个类同样是线程安全的,但是底层没有使用同步锁,因此在多线程环境下推荐使用ConcurrentHashMap。
ConcurrentHashMap底层的实现方式也是数组+链表+红黑树
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 package com.leo.map;import java.util.Map;import java.util.concurrent.ConcurrentHashMap;public class Demo7 { public static void main (String[] args) { Map<String, String> map = new ConcurrentHashMap <>(); map.put("10000" , "迪丽热巴" ); map.put("10010" , "古力娜扎" ); map.put("10086" , "马尔扎哈" ); for (Map.Entry<String, String> entry : map.entrySet()) { System.out.println(entry.getKey() + ":" + entry.getValue()); } } }
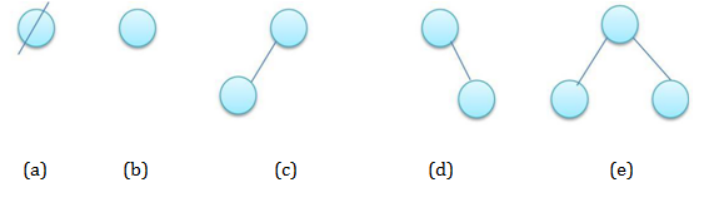
二叉树和红黑二叉树 二叉树 二叉树是一种树形的数据结构,一个节点有左右两个子节点
一般情况下,我们使用的都是 排序二叉树
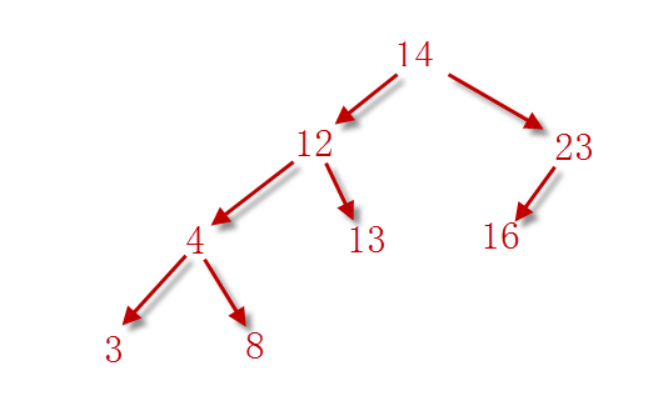
比如:我们要将数据【14, 12, 23, 4, 16, 13, 8, 3】存储到排序二叉树中,如下图所示:
我们最终发现,对于每一个节点来说,它的所有的左节点都比自己小,所有的右节点都比自己大,最终实现了一个排序的效果
当查询时,就可以使用二分查找法的思想
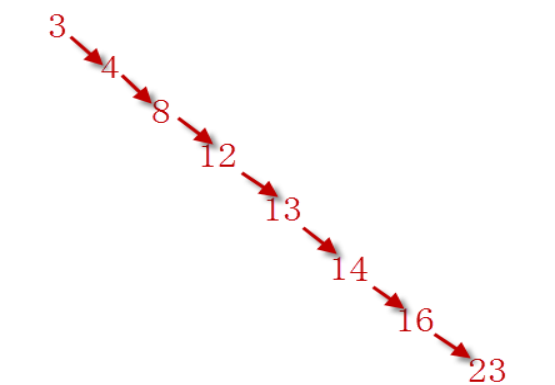
但是二叉树存在一个弊端,就是树结构不能保证平衡性。比如要将 【3,4,8,12,13,14,16,23】存储到二叉树中,最终形成了一个链表,就不具备二叉树的查询快的优点
平衡二叉树 平衡二叉树是一个很特殊的二叉树,在平衡二叉树中任何节点的两个子树的高度最大差别是1,所以也叫作高度平衡树。
在插入元素之后,会计算左子树和右子树的高度差,一旦高度差超过了2,就会进行 左旋或者右旋 ,通过旋转的手段重新平衡树结构。
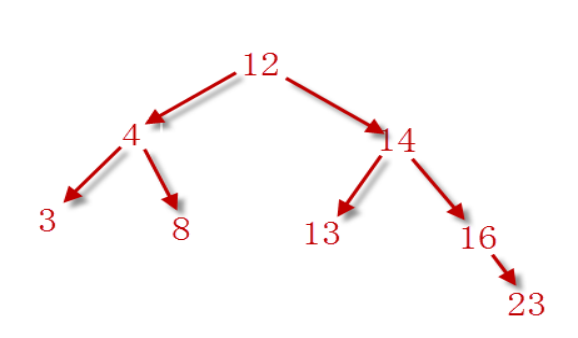
比如要将 【3,4,8,12,13,14,16,23】存储到平衡二叉树中
红黑二叉树 红黑二叉树是一个更特殊的二叉树,它也是个自平衡的二叉树,也有左旋和右旋的操作,此外,红黑二叉树的每一个节点都使用颜色去区分(红色和黑色),因此在自平衡的过程中还伴随着变色 的操作
红黑二叉树有以下几点要求
每个节点要么是红色,要么是黑色。
根节点永远是黑色的。
所有的叶节点都是空节点(即null),并且是黑色的。
每个红色节点的两个子节点都是黑色 (从每个叶子到根的路径上不会有两个连续的红色节点) 。
从任一节点到其子树中每个叶子节点的路径都包含相同数量的黑色节点。-> 新插入的节点一定是红色
红黑树的变换遵循以下的规则(不平衡时才进行)
插入节点的父节点和叔叔节点都是红色(或为空),解决方案是将父节点和叔叔节点变成黑色,爷爷节点变成红色(如果爷爷节点是根节点就不需要改变)
插入节点的父节点是红色,叔叔节点是黑色或者不存在,且插入节点是其父节点的右子节点,此时解决方案是以父节点为支点进行左旋
插入节点的父节点是红色,叔叔节点是黑色或者是空,且插入节点是父节点的左子节点,解决方案是将其父节点变成黑色,爷爷节点变成红色,以爷爷节点为支点进行右旋
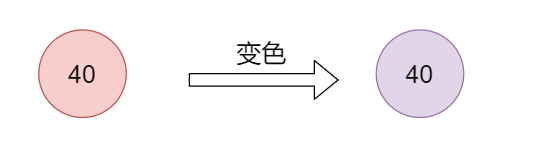
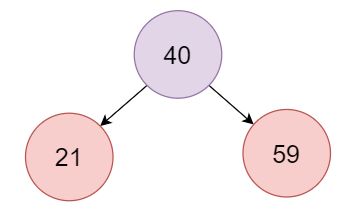
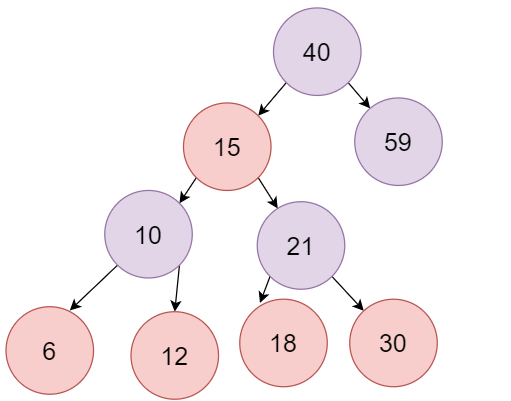
接下来以插入 【40、21、59、15、10、30、6、12、18、17】 为例
第一次插入40,新结点一定是红色节点。此时40节点是根节点,不满足2的需求,要进行变色,将这个节点变成黑色
下面插入21和59,红黑树依然平衡,不需要进行变换操作
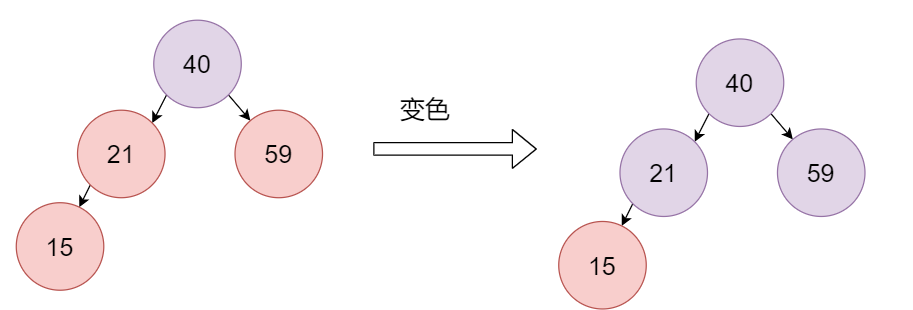
接下来插入15节点,此时不满足4,由于新插入的节点的父节点21和叔叔节点59也都是红色,此时就需要进行变换,将21和59变成黑色,40变成红色。此时由于40是根节点,再次将40变成黑色。
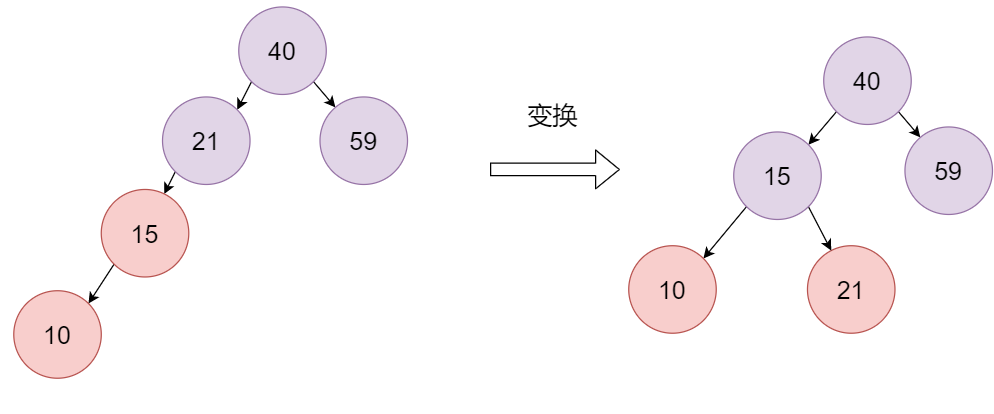
再插入10,插入后节点是红色,它的父节点15也是红色,且是左子节点,叔叔节点是空,将父节点变成黑色,将爷爷节点变成红色,然后以爷爷节点为支点进行右旋
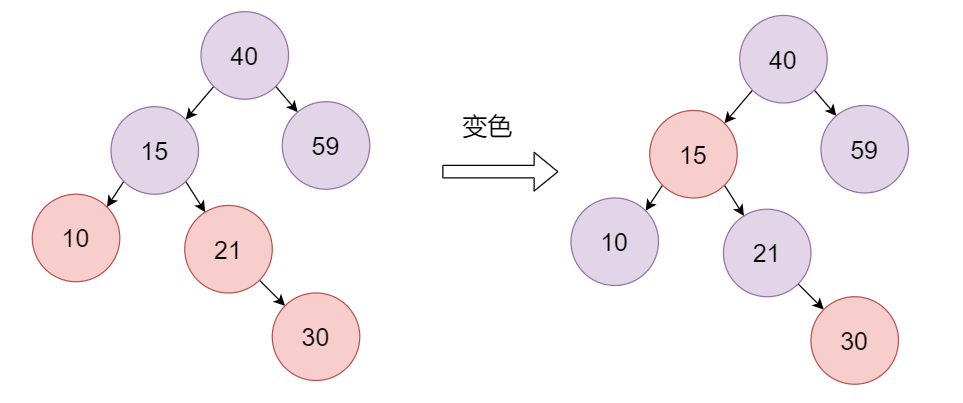
之后,再插入30,新插入节点是红色, 父节点和叔叔节点也都是红色,将父节点和叔叔节点变成黑色,爷爷节点变成红色
接下来插入6、12、18,插入后,树依然平衡,没有变化
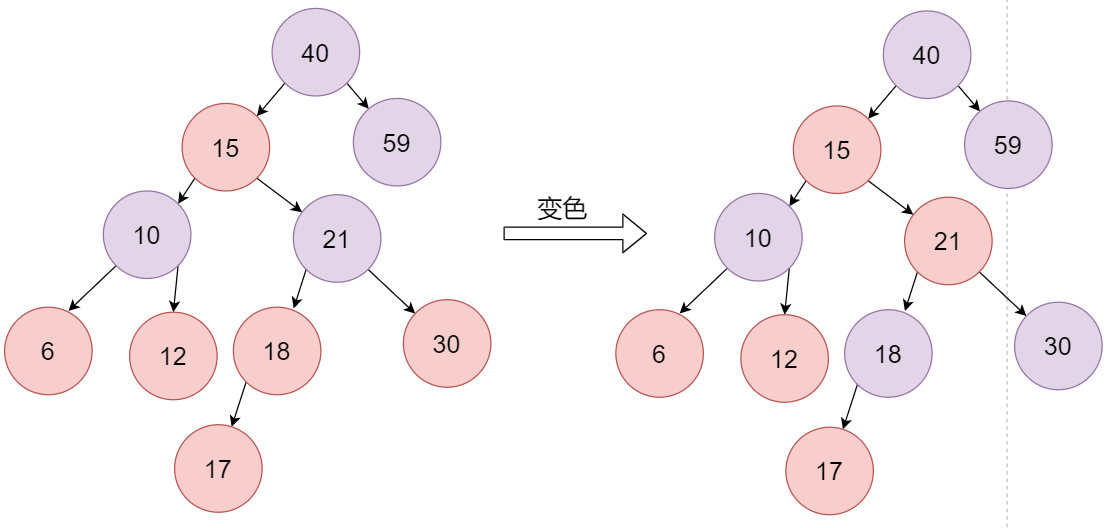
最后插入17,父节点和叔叔节点都是红色,此时将父节点和叔叔节点都变成黑色,爷爷节点变成红色
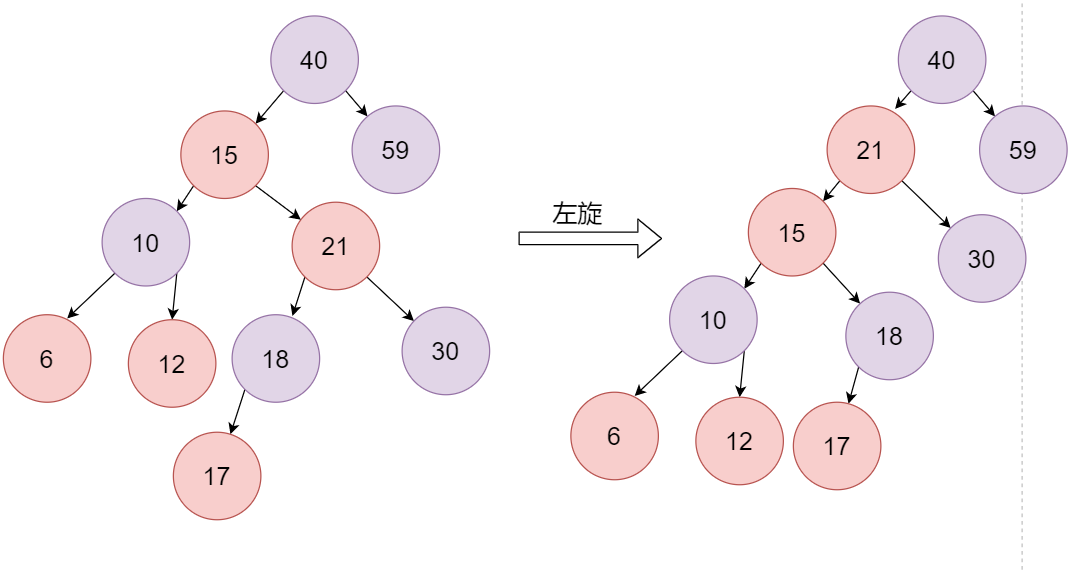
此时,21和15都是红色,存在了冲突,由于冲突是在插入节点时才会发生,此时可以将21看成新插入的节点,再做一系列的变换操作
新插入21,此时父节点是红色,叔叔节点是黑色,且新插入的节点是父节点的右子节点,此时以15为支点进行左旋
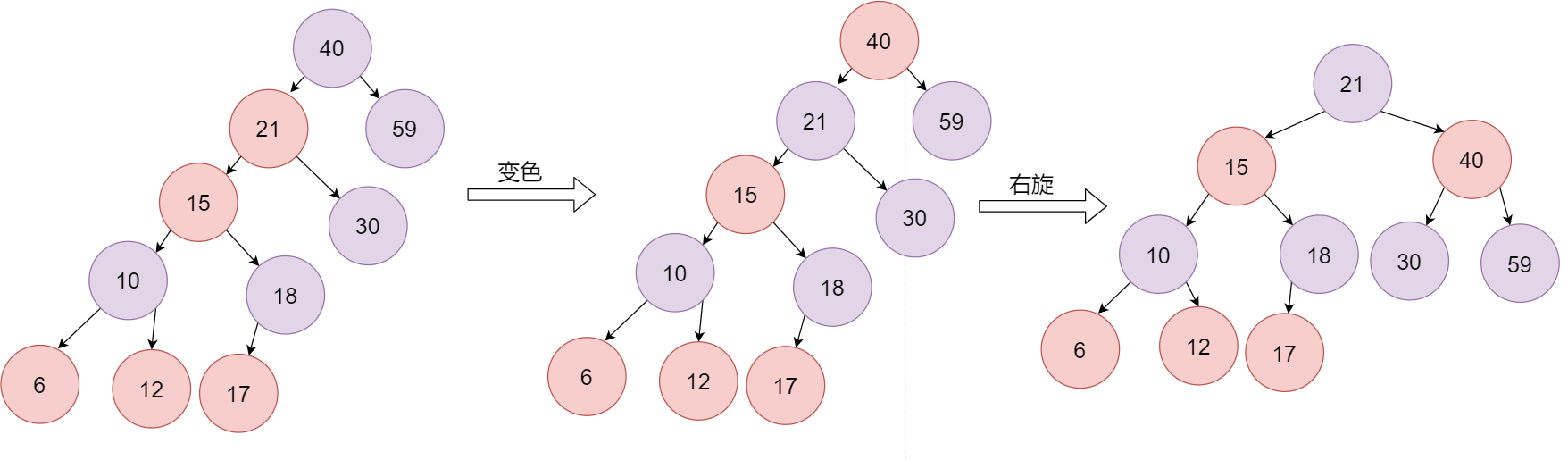
接下来15和21依然冲突,此时再将15看成新插入的节点,父节点是红色,叔叔节点是黑色,且新插入的节点是其父节点的左子节点,将父节点变成黑色,爷爷节点变成红色,再以爷爷节点为支点进行右旋
TreeMap 简单使用 TreeMap是一个可以排序的key-value集合,它底层是采用红黑二叉树实现的。这就意味着TreeMap会对插入的元素进行排序操作。排序可以按照自然排序,也可以传入比较器根据指定的规则进行排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 package com.leo.map;import java.util.Map;import java.util.TreeMap;public class Demo8 { public static void main (String[] args) { Map<String, String> map = new TreeMap <>(); map.put("10086" , "张三" ); map.put("10000" , "李四" ); map.put("10010" , "王五" ); System.out.println(map); } }
字符串按照字典顺序排序,数字按照从小到大排序,由于存在排序操作,所以TreeMap的key不能是null
内部比较器:Comparable接口 通过分析源码发现,TreeMap在put时会将待插入的key强转成Comparable,再根据比较的结果决定存储到节点的左边还是右边。
Comparable叫做内部比较器,内部维护了一个 compareTo 方法,会根据这个方法的结果决定排序结果。
如果想把一个对象用作TreeMap的key,这个对象对应的类就需要实现Comparable接口,并且重写compareTo方法
当compareTo方法返回值是负数,表示当前元素放到红黑树的左边,即逆序输出
当compareTo方法返回值是0,表示元素相同,仅存放第一个元素
当compareTo方法返回时是正数,表示放到红黑树的右边,即顺序输出
下面以Student为例,按照年龄的大小顺序排序
首先让Student实现Comparable接口
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 package com.leo.map;import java.util.Objects;public class Student implements Comparable <Student> { private String name; private int age; private double score; private String code; public Student (String name, int age, double score) { this .name = name; this .age = age; this .score = score; } public Student (String name, String code) { this .name = name; this .code = code; } @Override public boolean equals (Object o) { if (this == o) return true ; if (o == null || getClass() != o.getClass()) return false ; Student student = (Student) o; return code.equals(student.code); } @Override public int hashCode () { return Objects.hash(code); } public int getAge () { return age; } public void setAge (int age) { this .age = age; } public double getScore () { return score; } public void setScore (double score) { this .score = score; } public String getName () { return name; } public void setName (String name) { this .name = name; } public String getCode () { return code; } public void setCode (String code) { this .code = code; } @Override public String toString () { return "Student{" + "name='" + name + '\'' + ", age=" + age + ", score=" + score + ", code='" + code + '\'' + '}' ; } @Override public int compareTo (Student o) { if (this .age - o.age > 0 ) { return 1 ; }else if (this .age - o.age < 0 ) { return -1 ; } return 0 ; } }
下面是测试代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 package com.leo.map;import java.util.Map;import java.util.TreeMap;public class Demo9 { public static void main (String[] args) { Map<Student, Integer> map = new TreeMap <>(); map.put(new Student ("张三" , 23 , 100 ), 1 ); map.put(new Student ("李四" , 26 , 90 ), 2 ); map.put(new Student ("王五" , 24 , 120 ), 3 ); for (Map.Entry<Student, Integer> entry : map.entrySet()) { System.out.println(entry); } } }
外部比较器:Comparator接口 当我们通过内部比较器给某些类定义排序规则时,这些类就只能定义一种排序规则,如果想定义多种排序规则,就无法实现。
此外,Java中内置的一些类,比如String、Integer,内部已经实现了Comparable接口,拥有了排序的功能,且源码不可修改,此时如果想改变这些类的排序规则,就不能在Comparable上下手
此时就可以使用外部比较器Comparator接口
在创建TreeMap对象时,就可以传入一个Comparator的实现类对象,在这里定义排序规则
compare方法的运行机制与compareTo方法一致
下面我们编写代码,使用Integer的key,按照数字的大小,逆序排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 package com.leo.map;import java.util.Comparator;import java.util.Map;import java.util.TreeMap;public class Demo10 { public static void main (String[] args) { Map<Integer, Integer> map = new TreeMap <>(new Comparator <Integer>() { @Override public int compare (Integer o1, Integer o2) { if (o1 - o2 > 0 ) { return -1 ; }else if (o1 - o2 < 0 ) { return 1 ; } return 0 ; } }); map.put(2 ,2 ); map.put(3 ,3 ); map.put(1 ,1 ); map.put(0 ,0 ); for (Map.Entry<Integer, Integer> integerIntegerEntry : map.entrySet()) { System.out.println(integerIntegerEntry); } } }
总结:绝大多数情况下,都使用HashMap。如果想让Map的存取顺序一致,就使用LinkedHashMap,如果想对Key进行排序操作,就使用TreeMap,如果需要在多线程情况下保证线程安全,就使用ConcurrentHashMap。
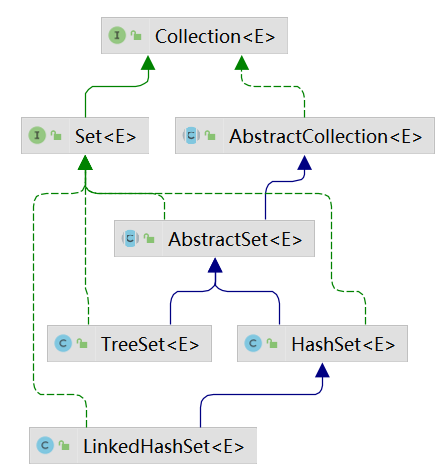
Set集合 Set集合介绍 Set接口继承自Collection接口,但是没有新增一些方法,与Collection保持完全一致。
Set集合的特点是无序、不可重复 。无序指的是没有序号,也就是指没有索引,不能通过索引操作元素,只能遍历。不可重复指的是不能插入重复元素,这里判断重复的依据是 equals和hashCode方法
Set集合常见的子类有 HashSet、LinkedHashSet、TreeSet
HashSet类详解 HashSet类是Set接口最常见的一个实现类,底层是采用HashMap实现的。HashSet不能保证存取顺序一致,HashSet中不能有重复元素
1 2 3 public boolean add (E e) { return map.put(e, PRESENT)==null ; }
HashSet底层实现非常简单,add方法就是把待添加的值作为map的key存储到map中去。这样就应用到了HashMap的key的特性,即:key不能保证存取顺序一致,且不能重复。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 package com.leo.set;import java.util.HashSet;import java.util.Set;public class Demo1 { public static void main (String[] args) { Set<String> set = new HashSet <>(); set.add("迪丽热巴" ); set.add("古力娜扎" ); set.add("马尔扎哈" ); set.add("真皮沙发" ); set.add("迪丽热巴" ); set.add("马尔扎哈" ); for (String s : set) { System.out.println(s); } } }
HashSet集合可以应用于List集合的去重操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 package com.leo.set;import java.util.ArrayList;import java.util.HashSet;import java.util.List;import java.util.Set;public class Demo2 { public static void main (String[] args) { List<String> list = new ArrayList <>(); list.add("迪丽热巴" ); list.add("古力娜扎" ); list.add("马尔扎哈" ); list.add("真皮沙发" ); list.add("迪丽热巴" ); list.add("马尔扎哈" ); System.out.println(list); Set<String> set = new HashSet <>(list); System.out.println(set); list.clear(); list.addAll(set); System.out.println(list); } }
LinkedHashSet HashSet不能保证元素的存取顺序一致,如果想保证存取顺序一致,就可以使用LinkedHashSet
LinkedHashSet底层是使用LinkedHashMap实现的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 package com.leo.set;import java.util.HashSet;import java.util.LinkedHashSet;import java.util.Set;public class Demo3 { public static void main (String[] args) { Set<String> set = new LinkedHashSet <>(); set.add("迪丽热巴" ); set.add("古力娜扎" ); set.add("马尔扎哈" ); set.add("真皮沙发" ); set.add("迪丽热巴" ); set.add("马尔扎哈" ); for (String s : set) { System.out.println(s); } } }
在list去重需求中,如果想要保证去重后顺序与list顺序一致,就可以使用LinkedHashSet
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 package com.leo.set;import java.util.*;public class Demo4 { public static void main (String[] args) { List<String> list = new ArrayList <>(); list.add("迪丽热巴" ); list.add("古力娜扎" ); list.add("马尔扎哈" ); list.add("真皮沙发" ); list.add("迪丽热巴" ); list.add("马尔扎哈" ); System.out.println(list); Set<String> set = new LinkedHashSet <>(list); System.out.println(set); list.clear(); list.addAll(set); System.out.println(list); } }
TreeSet TreeSet底层采用TreeMap实现,可以对存入的数据进行排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 package com.leo.set;import java.util.Set;import java.util.TreeSet;public class Demo5 { public static void main (String[] args) { Set<Integer> set = new TreeSet <>(); set.add(50 ); set.add(60 ); set.add(10 ); set.add(20 ); System.out.println(set); } }
TreeSet同样支持内部比较器和外部比较器
外部比较器案例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 package com.leo.set;import java.util.Comparator;import java.util.Set;import java.util.TreeSet;public class Demo6 { public static void main (String[] args) { Set<Integer> set = new TreeSet <>(new Comparator <Integer>() { @Override public int compare (Integer o1, Integer o2) { if (o1-o2 > 0 ) { return -1 ; }else if (o1 - o2 < 0 ) { return 1 ; } return 0 ; } }); set.add(50 ); set.add(60 ); set.add(10 ); set.add(20 ); System.out.println(set); } }
内部比较器案例,沿用上面的Student类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 package com.leo.set;import com.leo.map.Student;import java.util.Map;import java.util.Set;import java.util.TreeMap;import java.util.TreeSet;public class Demo7 { public static void main (String[] args) { Set<Student> set = new TreeSet <>(); set.add(new Student ("张三" , 23 , 100 )); set.add(new Student ("李四" , 26 , 90 )); set.add(new Student ("王五" , 24 , 120 )); for (Student student : set) { System.out.println(student); } } }
Set集合最大的应用场景就是给List去重,如果在编写代码时需要考虑代码的健壮性,可以在某些场景使用Set集合,比如查询商品时,可能商品存在重复数据,但是使用Set集合存储,就能规避重复数据
大部分情况下,可以直接使用HashSet
如果想要让元素的存取顺序一致,就使用LinkedHashSet
如果想要让元素能够排序,就使用TreeSet
Collections工具类 排序sort sort方法的作用是对List进行排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 package com.leo.collections;import java.util.ArrayList;import java.util.Collections;import java.util.Comparator;import java.util.List;public class Demo1 { public static void main (String[] args) { List<Integer> list = new ArrayList <>(); list.add(50 ); list.add(20 ); list.add(10 ); list.add(70 ); list.add(80 ); System.out.println(list); Collections.sort(list); System.out.println(list); Collections.sort(list, new Comparator <Integer>() { @Override public int compare (Integer o1, Integer o2) { if (o1-o2 > 0 ) { return -1 ; }else if (o1-o2 < 0 ) { return 1 ; } return 0 ; } }); System.out.println(list); } }
混排shuffle 混排的作用是把一个集合顺序打乱。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 package com.leo.collections;import java.util.ArrayList;import java.util.Collections;import java.util.List;public class Demo2 { public static void main (String[] args) { List<String> list = new ArrayList <>(); list.add("A" ); list.add("2" ); list.add("3" ); list.add("4" ); list.add("5" ); list.add("6" ); list.add("7" ); list.add("8" ); list.add("9" ); list.add("10" ); list.add("J" ); list.add("Q" ); list.add("K" ); System.out.println(list); Collections.shuffle(list); System.out.println(list); Collections.shuffle(list); System.out.println(list); } }
反转reverse 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 package com.leo.collections;import java.util.ArrayList;import java.util.Collections;import java.util.List;public class Demo3 { public static void main (String[] args) { List<String> list = new ArrayList <>(); list.add("A" ); list.add("2" ); list.add("3" ); list.add("4" ); list.add("5" ); list.add("6" ); list.add("7" ); list.add("8" ); list.add("9" ); list.add("10" ); list.add("J" ); list.add("Q" ); list.add("K" ); System.out.println(list); Collections.reverse(list); System.out.println(list); } }
替换fill 替换集合中所有的元素
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 package com.leo.collections;import java.util.ArrayList;import java.util.Collections;import java.util.List;public class Demo4 { public static void main (String[] args) { List<Integer> list = new ArrayList <>(); list.add(1 ); list.add(2 ); list.add(3 ); list.add(4 ); System.out.println(list); Collections.fill(list, 666 ); System.out.println(list); } }
随堂练习
统计一段文本中每个字符出现的次数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 package com.leo.test;import java.util.HashMap;import java.util.Map;public class Test1 { public static void main (String[] args) { String test = "DProgram FilesJavajdk-17.0.4binjava.exe" ; Map<Character, Integer> map = new HashMap <>(); for (char c : test.toCharArray()) { Integer count = map.get(c); if (count == null ) { count = 0 ; } count++; map.put(c, count); } for (Map.Entry<Character, Integer> entry : map.entrySet()) { System.out.println(entry.getKey()+":" +entry.getValue()); } } }
假如有以下email数据“aa@sohu.com ,bb@163.com ,cc@sina.com ,..”现需要把email中的用户部分和邮件地址部分分离,分离后以键值对应的方式放入HashMap
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 package com.leo.test;import java.util.HashMap;import java.util.Map;public class Test2 { public static void main (String[] args) { String str = "aa@sohu.com,bb@163.com,cc@sina.com" ; Map<String, String> map = new HashMap <>(); for (String s : str.split("," )) { String[] arr = s.split("@" ); map.put(arr[0 ], arr[1 ]); } System.out.println(map); } }
现有一些学生的成绩信息,按照班级对这些学生进行分组,并统计每一个班级的平均分、中位数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 package com.leo.test;import java.util.*;public class Test3 { public static void main (String[] args) { List<Student> list = new ArrayList <>(); list.add(new Student ("1班" , 100 )); list.add(new Student ("1班" , 90 )); list.add(new Student ("2班" , 85 )); list.add(new Student ("2班" , 76 )); list.add(new Student ("1班" , 95 )); list.add(new Student ("3班" , 90 )); list.add(new Student ("3班" , 100 )); list.add(new Student ("1班" , 99 )); list.add(new Student ("2班" , 98 )); list.add(new Student ("3班" , 60 )); list.add(new Student ("4班" , 85 )); list.add(new Student ("4班" , 74 )); list.add(new Student ("4班" , 62 )); Set<String> roomSet = new HashSet <>(); for (Student student : list) { String room = student.getRoom(); roomSet.add(room); } System.out.println(roomSet); Map<String, List<Student>> map = new HashMap <>(); for (String s : roomSet) { map.put(s, new ArrayList <>()); } for (Student student : list) { List<Student> tmpList = map.get(student.getRoom()); tmpList.add(student); } for (Map.Entry<String, List<Student>> entry : map.entrySet()) { System.out.println(entry.getKey()); List<Student> value = entry.getValue(); Collections.sort(value, new Comparator <Student>() { @Override public int compare (Student o1, Student o2) { if (o1.getScore() - o2.getScore() >0 ) { return 1 ; }else if (o1.getScore() - o2.getScore() < 0 ) { return -1 ; } return 0 ; } }); int sum = 0 ; for (Student student : value) { sum += student.getScore(); } System.out.println("平均分:" + (sum*1.0 / entry.getValue().size())); System.out.println("中位数:" + value.get(value.size()/2 ).getScore()); } } private static class Student { private String room; private Integer score; public Student (String room, Integer score) { this .room = room; this .score = score; } public String getRoom () { return room; } public void setRoom (String room) { this .room = room; } public Integer getScore () { return score; } public void setScore (Integer score) { this .score = score; } } }
“验签”是软件开发中的一种数据安全策略,指我方提供方法给其他团队使用时,对方除了需要将参数进行明文传递外,还需要传递一个“签名”,这个签名是根据参数按照一定规则生成的字符串,我方接收到参数后,会按照相同的规则处理参数,最终对比两份签名是否一致。现有一个签名算法,要求:将参数按照参数名称进行排序,将排序后的参数按照key1value1key2value2….形式进行排序,将排序后的字符串中每一个字符+1,最后拼接上timestamp=时间戳。编写程序实现这个签名算法,并提供验签工具。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 package com.leo.test;import java.util.HashMap;import java.util.Map;import java.util.TreeMap;public class Test4 { public static void main (String[] args) { Map<String, String> map = new HashMap <>(); map.put("id" , "123" ); map.put("name" , "张三" ); map.put("age" , "23" ); Map<String, String> param = new TreeMap <>(map); StringBuilder s = new StringBuilder (); for (Map.Entry<String, String> entry : param.entrySet()) { s.append(entry.getKey()).append(entry.getValue()); } StringBuilder s2 = new StringBuilder (); for (char c : s.toString().toCharArray()) { char ch = (char ) (c+1 ); s2.append(ch); } s2.append("timestamp=" ).append(System.currentTimeMillis()); boolean flag = method(param, s2.toString()); System.out.println(flag); } public static boolean method (Map<String, String> param, String digest) { StringBuilder s = new StringBuilder (); for (Map.Entry<String, String> entry : param.entrySet()) { s.append(entry.getKey()).append(entry.getValue()); } int index = digest.lastIndexOf("timestamp" ); String substring = digest.substring(0 , index); char [] arr1 = s.toString().toCharArray(); char [] arr2 = substring.toCharArray(); for (int i = 0 ; i < arr1.length; i++) { if (arr1[i] + 1 != arr2[i]) { return false ; } } return true ; } }
超时会员管理系统 需求分析
使用分层开发:表示层(测试类)、业务层(超市会员信息管理类)、实体层(超市会员信息类)
使用集合的相关方法实现超市会员信息管理系统的查看、新增、删除,查看超市会员信息之前需要对集合进行初始化操作
新增超市会员信息时,随机产生1000-9999之间的会员ID
删除超市会员信息时,需要先判断该超市会员信息是否已经存在,存在才可以删除,删除时提示是否删除,确认后再删除并显示删除后的所有会员信息
选择退出功能则程序结束
代码编写 User
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 package com.leo.market.pojo;import java.util.Objects;public class User { private Integer id; private String account; private String type; private Integer score; private String status; public User () { } public User (Integer id, String account, String type, Integer score, String status) { this .id = id; this .account = account; this .type = type; this .score = score; this .status = status; } public Integer getId () { return id; } public void setId (Integer id) { this .id = id; } public String getAccount () { return account; } public void setAccount (String account) { this .account = account; } public String getType () { return type; } public void setType (String type) { this .type = type; } public Integer getScore () { return score; } public void setScore (Integer score) { this .score = score; } public String getStatus () { return status; } public void setStatus (String status) { this .status = status; } @Override public boolean equals (Object o) { if (this == o) return true ; if (o == null || getClass() != o.getClass()) return false ; User user = (User) o; return Objects.equals(id, user.id); } @Override public int hashCode () { return Objects.hash(id); } }
MarketManager
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 package com.leo.market.service;import com.leo.market.database.Database;import com.leo.market.pojo.User;import javax.xml.crypto.Data;import java.util.List;public interface UserService { List<User> findAll () ; void save (User user) ; default boolean deleteById (int id) { User user = new User (); user.setId(id); return Database.LIST.remove(user); } }
Database
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 package com.leo.market.database;import com.leo.market.pojo.User;import com.leo.market.utils.IdUtils;import java.util.ArrayList;import java.util.List;public class Database { public static final List<User> LIST = new ArrayList <>(); static { LIST.add(new User (IdUtils.getId(), "冯程程" , "铂金卡" , 2000 , "合法账户" )); LIST.add(new User (IdUtils.getId(), "孙悟空" , "钻石卡" , 5000 , "被禁账户" )); LIST.add(new User (IdUtils.getId(), "张巧巧" , "黄金卡" , 1000 , "合法账户" )); } }
UserService
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 package com.leo.market.service;import com.leo.market.database.Database;import com.leo.market.pojo.User;import javax.xml.crypto.Data;import java.util.List;public interface UserService { List<User> findAll () ; void save (User user) ; default boolean deleteById (int id) { User user = new User (); user.setId(id); return Database.LIST.remove(user); } }
UserServiceImpl
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 package com.leo.market.service.impl;import com.leo.market.database.Database;import com.leo.market.pojo.User;import com.leo.market.service.UserService;import java.util.List;public class UserServiceImpl implements UserService { @Override public List<User> findAll () { return Database.LIST; } @Override public void save (User user) { Database.LIST.add(user); } }
IdUtils
1 2 3 4 5 6 7 8 9 10 11 12 13 package com.leo.market.utils;public final class IdUtils { private IdUtils () { } public static Integer getId () { return (int )(Math.random() * 9000 + 1000 ); } }